


The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
本篇要解决的问题
本篇旨在解决通过RL提升推理能力时的一个核心障碍:熵策略崩溃。
具体而言,问题在以下的几个方面:
-
熵的急剧下降与性能饱和:在大量的RL实验中,研究者一致观察到,若不进行干预,策略熵会在训练早期急剧下降,导致模型变得“过度自信”
。这种探索能力的减弱总是伴随着模型性能的饱和,即模型无法进一步提升
。
性能提升受限于熵的消耗:论文发现,模型的下游性能(
R)和策略熵(H)之间存在一个经验性的指数关系:R = -a * exp(H) + b。这表明,模型的性能提升是通过“交易”或消耗策略熵换来的,因此性能的上限被熵的耗尽所限制 。当熵完全耗尽时(H=0),性能达到可预测的天花板R = -a + b。常规熵正则化方法效果不佳:尽管在传统RL中,熵正则化是常用手段,但论文指出,简单地将这些方法(如熵损失或KL惩罚)应用于LLMs效果不佳,要么对超参数高度敏感,要么会损害模型性能 。
关于问题上的一些洞察:
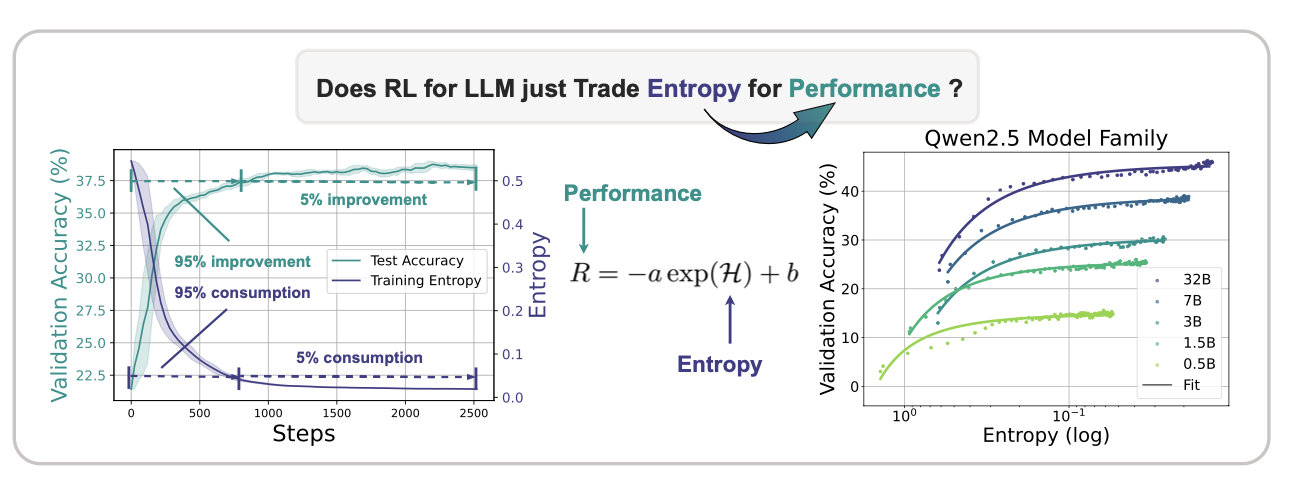
通过这张图,我们可以很明显的看出,
模型的熵和模型在下游任务上的准确率成指数关系。
对于我的理解来说,就是模型发现了一些比较优势的方法,从而持续的使用。但是这种确实很容易陷入局部的最优。
方法论
作者提出,熵和得到的奖励可以用以下关系预测:
作者分别对代码任务和数学任务进行了实验,得出的结果如下
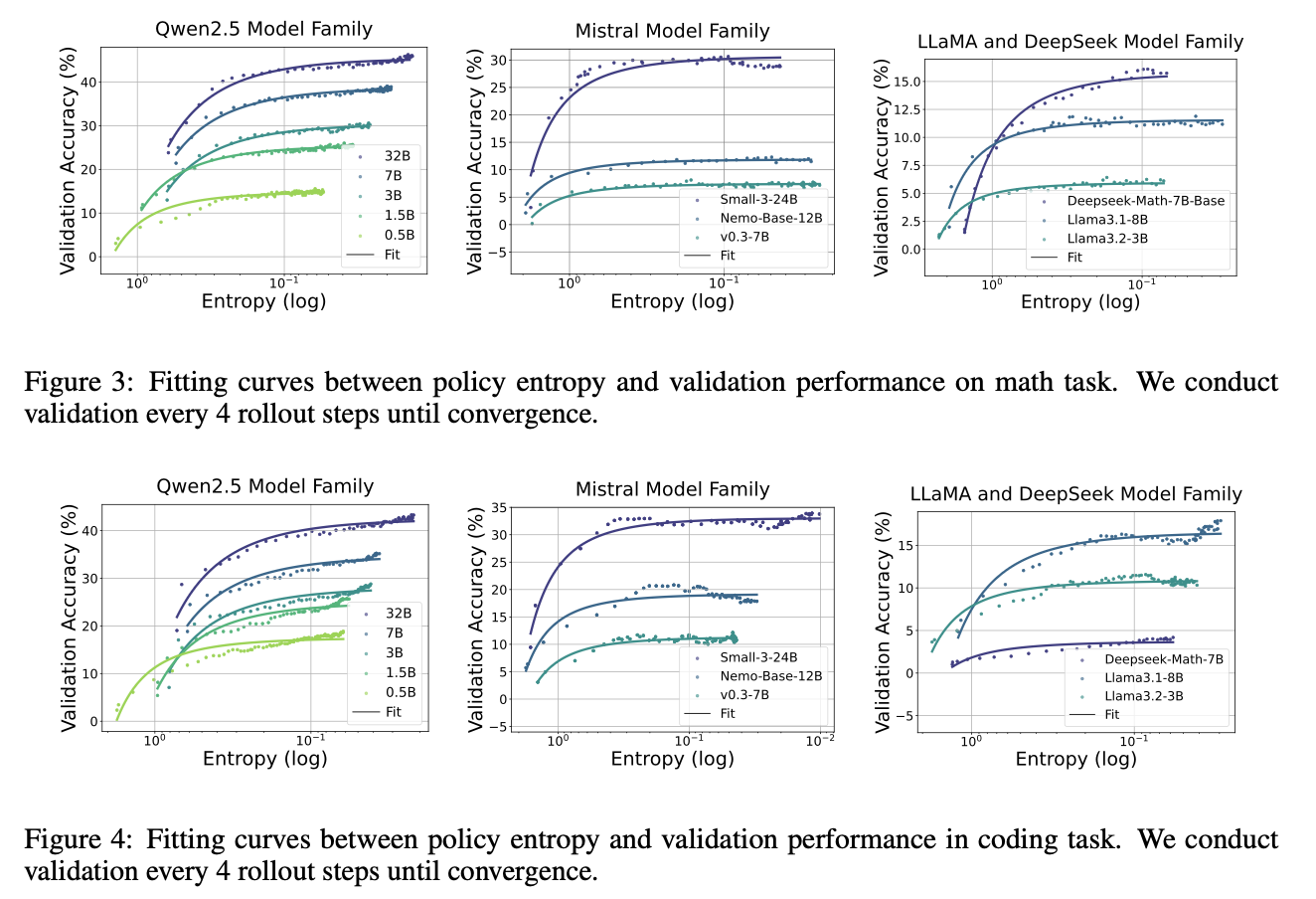
但是这里有一个简单的疑虑,并不一定是指数的关系吧?实验中没有体现出和指数的线性关系。也可能只是我的要求太过于苛刻了。
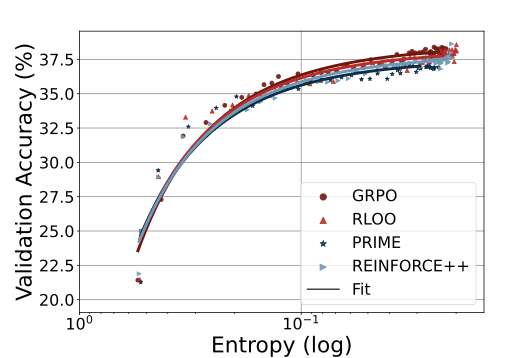
另外,作者还对不同的RL算法进行了尝试,发现,无论是怎样的RL算法,都会导致指数级别的熵-性能转换。这表明,系数a和b反映了策略模型和训练数据的某些内在属性。使得不同的模型可以有不同的用熵换取分数的能力。
但是这里的拟合有局限性,对于其他的on-policy算法,在使用不同的数据策略或者不同的模型之后,会有不同的熵变化模式。
另外,作者还提出了非常新颖的概念,就是,RL是否让基础模型超越了它原来的“天花板”。
根据熵减少的视角,那么确实,模型的性能有其天花板的存在。并且这个天花板和RL无关,而是模型自身的“熵机制”导致的。
特别的,作者给出了一个引理来说明熵的改变。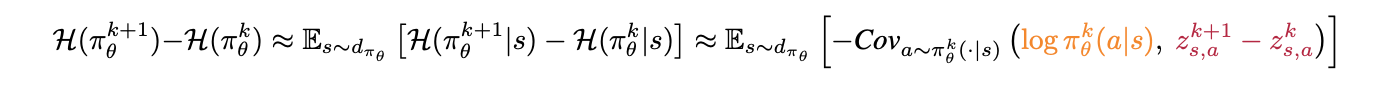
这个公式说明,前后的熵的变化量和当前动作的概率和logit的前后变化的无关性直接相关。这符合我们的直觉。当这个动作概率很低,但logit变化很大,那么熵的变化也很大。
当然,这个前后的变化的,我们完全可以用优势函数A来衡量。因此我们可以得到:
为此,作者也做了个实验来验证这个结论: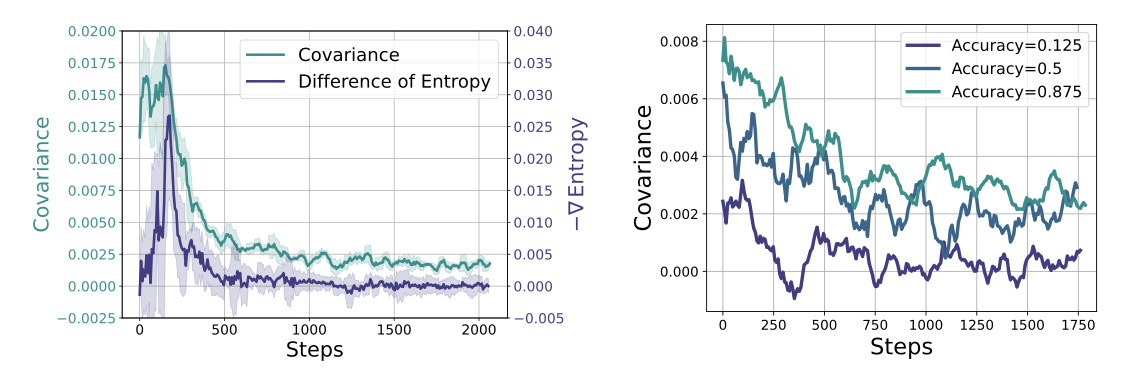
实验使用GRPO算法。左图可以看出,Cov项和熵具有高度的相关性。这和我们的理论推导相符。另外,作者还补充了右图,作者把训练数据分为三个难度,可以看出,高难度的样本,往往容易导致Cov项比较小。这和直觉相符,因为高概率的回答,并不一定和答案相符。低难度的样本往往cov项较大。
这也回答了LIMO这篇文章所提出的,高难度,高质量的训练数据,往往可以更可靠的提升模型的性能。因为对于不同数据而言,熵的变化会更缓慢,模型可以学到更多不同的表述。
明确了以上这些motivation,作者提出,既然就是Cov项导致了模型学不好,那么我不如就把他加入模型的训练过程得了。以此,让模型不能够通过很高概率且正确的回答就大幅度的降低熵。
为了解决这个问题,作者首先尝试了熵正则化的方法,即在loss中加入鼓励熵增大的项。但是效果很差,对超参数过于敏感且性能下降了。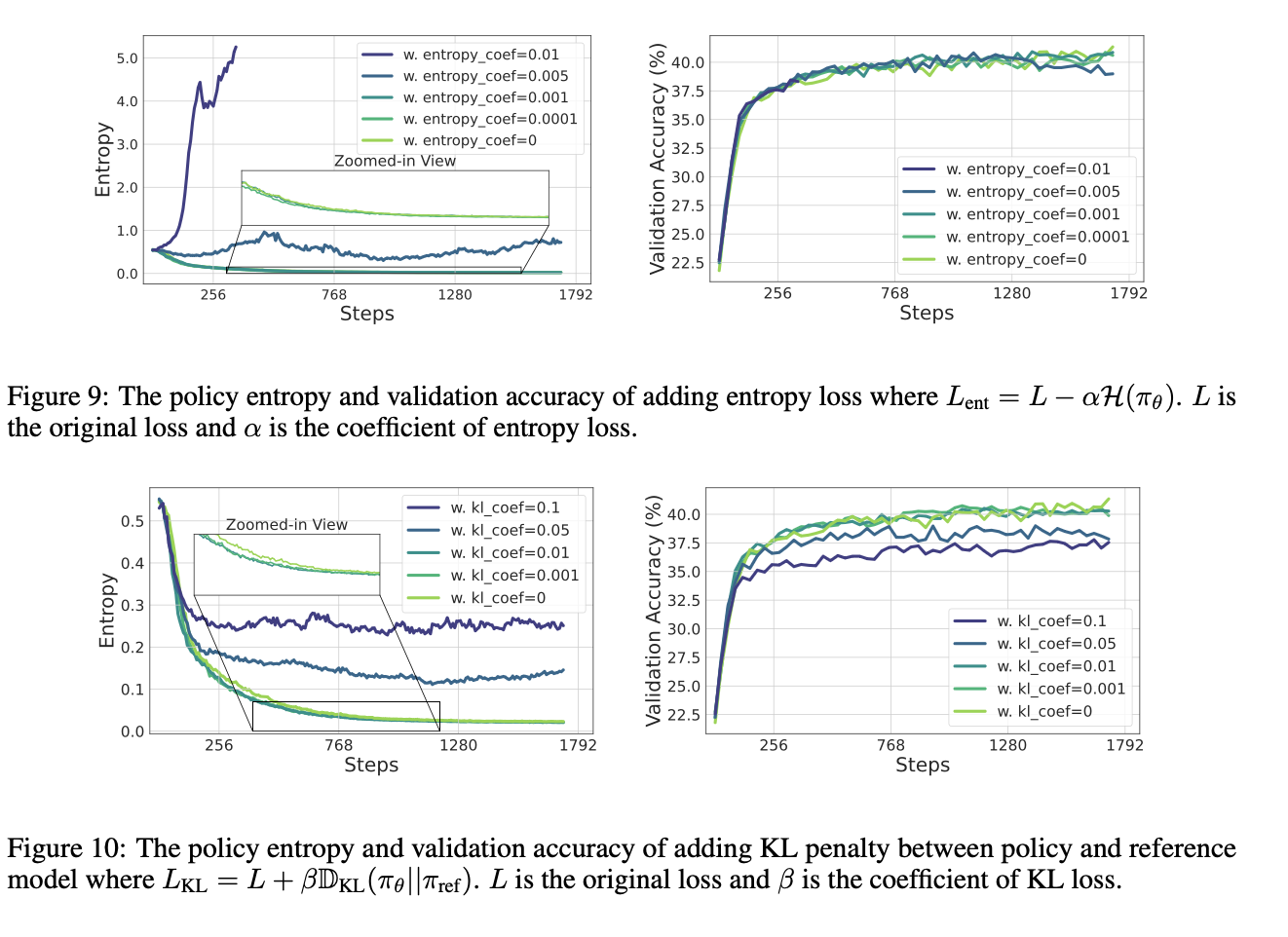
于是作者转而处理目标函数。

作者用了一个比较粗暴的方法,直接把高Cov的token给剔除出去,不参与训练了。这是第一个解决的方法。

这是作者提出的第二个解决方法,即筛选出Cov项的排名,然后在loss中,对Cov比较高的前几项,施加一个KL散度惩罚,让他们的变化要少一点。
实验方法和结果
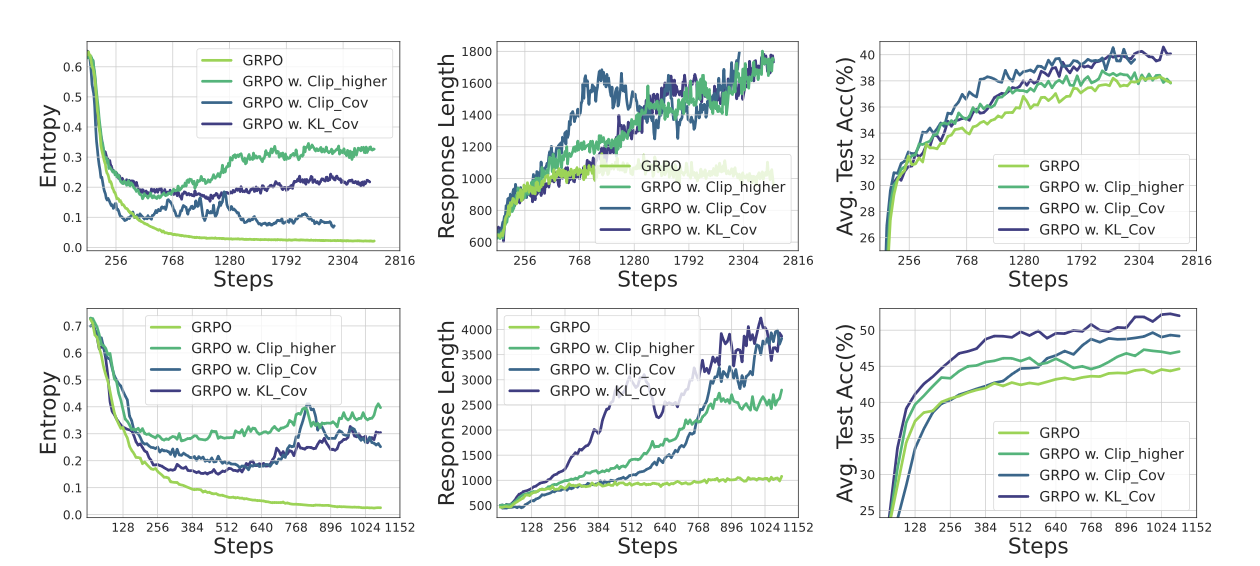
效果超过GRPO算法。可以说表现很好了。并且也提高了accuracy。
DAST: Difficulty-Adaptive Slow Thinking for Large Reasoning Models
要解决的问题
对于不同难度的问题,现有的方法都进行同样的长度限制,这是不符合常理的。我们要鼓励难的问题思考长一点,短的问题思考少一点。
方法论
通过计算一个教师模型的平均思考长度,作为衡量标准。
构建针对不同问题的长度的预算。
然后利用偏好学习进行微调。
具体的奖励是: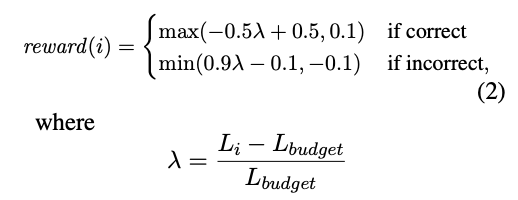
最后通过SimPO算法进行微调。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

