


Reasoning with Reinforced Functional Token Tuning
论文主要内容总结
这篇论文的核心是提出了一个名为 强化功能性词元微调(Reinforced Functional Token Tuning, RFTT) 的新颖框架,旨在通过一种高效的自我博弈(self-play) 机制,显著提升较小规模语言模型(LLM,特指7B-8B级别)的复杂推理能力。
论文指出,现有提升LLM推理能力的方法要么依赖昂贵的人工或超强模型标注的数据,要么采用效率低下的树搜索方法,这些方法因LLM固有的生成偏好和巨大的搜索空间而效果不佳 。RFTT框架通过将推理的“元认知”能力
内化为模型自身的技能来解决这些问题,为开发资源高效且推理能力强大的小型LLM提供了一条新路径。
创新点 (Innovation Points)
功能性词元(Functional Tokens):这是本文最核心的创新。论文没有使用外部的自然语言提示来引导推理,而是设计了一组可学习的、代表特定推理功能的特殊词元(如
<analyze>,<verify>,<refine>等),并将其直接加入到模型的词汇表中 。这使得模型能够像调用函数一样,自主地、结构化地规划其推理过程。将推理动作化,缩小搜索空间:通过引入功能性词元,原本在整个词汇表(数万个词元)中进行的树搜索,被极大地简化为在仅有的几个功能性词元中进行选择。这从根本上解决了树搜索面临的组合爆炸问题,显著提高了探索效率 。
两阶段自我提升框架 (RFTT):论文设计了一个包含“预热”和“在线强化”的完整学习流程。模型首先通过监督微调(SFT)学会功能性词元的“语法”,然后通过强化学习(RL)在自我博弈中精通运用这些词元的“策略” 。(个人认为这里是从DeepSeek里面学来的)
模拟人类思考的数据生成范式:在SFT预热阶段,论文提出了一种独特的自生成数据方法。该方法通过MCTS故意构造出包含“尝试-犯错-反思-修正”的复杂推理路径,并用功能性词元进行标注 。这使得模型能够学习到更接近人类真实思考过程的、鲁棒的推理模式。
工作流 (Workflow)
RFTT框架的工作流分为清晰的两个阶段:
第一阶段:监督微调预热 (SFT Warmup) - “学习语言”
这个阶段的目标是让模型理解并学会使用这套新的“功能性语言”。
探索与生成:使用蒙特卡洛树搜索(MCTS),但由功能性提示(如“请分析问题”)而非词元来引导,为给定的数学问题生成一棵包含多种正确和错误解题思路的推理树 。
反思与修正:
从树中挑选出一条高质量的正确路径和一条部分正确的错误路径 。
通过一个“交叉验证”提示(如“对比正确步骤,当前步骤错在哪里?”),让模型生成一段自我验证和反思的文本 。
合并与标注:
将“正确的开头 -> 错误的步骤 -> 自我反思 -> 修正后的步骤”拼接成一条完整的、复杂的推理链 。
使用功能性词元(如
<verify>...</verify>)将路径中的相应部分包裹起来,形成结构化的训练数据。
模型训练:在这些自生成并标注好的数据上对LLM进行监督微调。
第二阶段:在线强化学习 (Online RL) - “精通策略”
这个阶段的目标是让模型通过自我博弈来精通这套“功能性语言”。
自主探索:经过SFT预热后,模型不再需要外部提示。它在解决新问题时,会使用MCTS作为其思考框架,自主地从词汇表中采样功能性词元来决定下一步的推理动作(是继续
<next_step>还是进行<verify>)。奖励与优化:
模型根据生成的完整推理路径是否得到正确答案来获得奖励信号。
使用强化学习算法(Reinforce++)来更新模型参数,目的是增加那些能够导向高奖励的“功能性词元序列”被采样的概率。
自我迭代提升:通过这个“探索-奖励-更新”的闭环,模型不断优化其选择推理策略的能力,从而实现推理能力的持续自我提升 。
GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
一句话,就是把GRPO的组优势的思想,放到了A2C算法中。
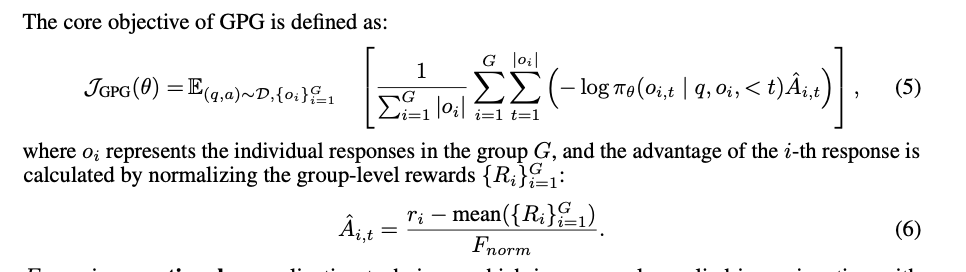
更多的,它魔改了一下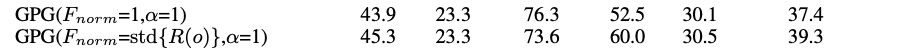
作者自己的结果也证明了这一点,是标准差的形式,跑分的结果基本都要比为1的结果要好一点。
其次,它洞察到,如果组内所有的结果都是对的,或者组内的结果都是错的,那么这个组对于梯度是没有贡献的。因此,在分布式训练框架中,需要对总体的loss乘以一个系数,即
同时,组式的方法还容易引入高方差的问题,如果大部分的组的结果都是0,那么刚刚乘的那个系数,会使得少部分的结果的梯度被放大很多倍。比如假如100个样本中,98个样本是无效的。那么最后的两个结果的参考性会被放大50倍,这会导致训练不稳定。
因此,它使用了一个阈值,当且仅当一个批次中的有效样本比率在60%以上,才进行梯度更新。
如果低于阈值,那么将有效样本累计,与后续采样的批次合并,一致直到最后的批次中有效样本的比例超过阈值。
思想总结:
GPG的核心创新点
GPG方法通过一系列环环相扣的设计,实现了一个既简单又强大的强化学习微调框架。其创新点主要体GPG方法通过一系列环环相扣的设计,实现了一个既简单又强大的强化学习微调(RL Fine-tuning)框架。其创新点主要体现在以下三个层面:
框架极简化,回归策略梯度本质 不同于您笔记中提到的A2C,GPG实际上回归并简化了更基础的策略梯度(Policy Gradient, PG)算法 。它通过移除复杂的组件,实现了框架的极简化:
无需评论家(Critic)和参考模型:GPG完全摒弃了用于评估状态价值的评论家模型和用于约束策略更新的参考模型 。
无需代理损失和KL约束:它不像PPO或GRPO那样依赖复杂的代理损失函数(surrogate loss)和KL散度约束,而是直接优化原始的RL目标 。
洞察并修正梯度估计偏差(核心创新) 这是GPG方法最关键的洞察。作者发现,当一个“组”内的所有回答奖励相同时(全对或全错),其优势(Advantage)为0,导致该组对梯度的贡献也为0 。标准的梯度平均算法会因此系统性地低估梯度的真实大小。GPG的解决方案是:
- 提出精确梯度估计(AGE):通过为总损失乘以一个修正系数
α=B/(B-M) 来进行校正
。其中
B是批次中的问题(prompt)总数,M是梯度为0的无效问题数。这个简单的系数从理论上消除了梯度偏差,带来了显著的性能提升 。
- 提出精确梯度估计(AGE):通过为总损失乘以一个修正系数
α=B/(B-M) 来进行校正
。其中
为修正机制引入配套的方差控制 作者意识到,虽然AGE是无偏的,但在有效样本极少的情况下,极大的
α系数会放大梯度噪声,导致训练不稳定 。为此,GPG设计了一套稳健的方差控制机制:设置有效样本阈值
β_th:只有当一个批次中有效样本的比例超过一个阈值(例如60%)时,才进行梯度更新 。累积与重采样:如果比例低于阈值,当前批次的有效样本会被缓存并与后续新采样的批次合并,直到合并后的“超级批次”满足阈值要求,才进行一次稳定、低方差的梯度更新 。
关于您提到的
std恰好起到了某种类似梯度修正的效果,但这不如其提出的AGE方法来得直接和根本
。
GPG的工作流 (Workflow)
结合其创新点,GPG的完整工作流程可以概括为以下五个步骤:
采样与评估 对于一个批次(Batch)的
B个问题,模型为每个问题生成一个组(Group)的G个回答。随后,根据预设的奖励函数(如准确率)为所有B*G个回答打分 。计算优势与判断有效性 对每个组,计算其内部每个回答的优势值
 = r_i - mean({R})。同时,统计该批次中,优势值全部为0的无效问题(组)数量M。检查方差与条件性重采样 计算有效问题(组)的比例
(B-M)/B。如果比例 >
β_th:则判定该批次足够稳定,可以进入下一步。如果比例 ≤
β_th:则触发方差控制机制。将当前批次的有效样本暂存,与下一批次合并,并重复步骤1-3,直到满足阈值条件 。
计算修正后的总损失 当一个批次通过方差检查后,计算梯度修正系数
α = B / (B - M)。然后,将该系数与标准的策略梯度损失相乘,得到最终需要优化的总损失 。反向传播与更新 对这个被
α修正过的、无偏且低方差的总损失执行反向传播,更新模型的参数。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

