


1. 定义与动机 (Definition & Motivation)
定义:数据库系统如何将数据在物理磁盘上进行组织、存储和管理,以及如何将数据从磁盘读取到内存中。
动机 (Motivation):
最小化 I/O:磁盘读写速度远慢于内存。数据库系统的首要目标是尽可能减少磁盘和内存之间的数据块(Block)传输次数。
空间管理:需要高效地在定长或变长记录中管理空闲空间,防止碎片化。
2. 核心概念梳理 (Core Concepts)
2.1 存储访问与缓冲区管理 (Storage Access)
块 (Block):数据库文件被划分为定长的存储单元。它是存储分配和数据传输的基本单位。
缓冲区管理器 (Buffer Manager):负责在内存中分配缓冲区空间,决定哪些块调入内存,哪些块写回磁盘。
关键:替换策略 (Replacement Policies)
| 策略 | 说明 | 适用性/缺点 |
|---|---|---|
| LRU (最近最少使用) | 淘汰最久未被访问的块 | OS常用,但DB慎用。对于重复扫描(如嵌套循环连接),会导致频繁换入换出 (Thrashing)。 |
| MRU (最近最常使用) | 淘汰最近被访问的块 | DB推荐。对于一次性扫描的数据,用完立即丢弃是更好的选择。 |
| Toss-immediate | 立即丢弃 | 一旦块中的最后一个元组处理完毕,立即释放空间。 |
| Pinned Block | 钉住 | 此时不允许写回磁盘的块(例如正在进行读写操作时,防止数据不一致)。 |
2.2 文件中的记录组织 (Organization of Records in Files)
A. 定长记录 (Fixed-Length Records)
存储方式:简单的存储,第
条记录从字节 开始。 难题:删除中间记录会留出空洞。
解决方案:
移动最后一条记录:用最后一条记录填补空洞(开销小)。
自由链表 (Free List):记录头存储第一个空闲位置,空闲位置存储下一个空闲位置的指针(维护一个空闲位置链)。
B. 变长记录 —— 分槽页结构 (Slotted Page Structure)
这是数据库处理变长数据的标准方式。
结构组成:
Block Header:位于页头。存储记录数、空闲空间末尾指针、每条记录的
(位置, 大小)。Records:从页尾向页头生长。
Free Space:位于 Header 和 Records 中间。
核心优势:间接寻址。记录可以在页内移动(整理碎片),只需更新 Header 中的指针。指向该记录的外部指针不需要改变。
2.3 文件的组织形式 (File Organization)
堆文件 (Heap):记录可以放在任何有空间的块中,无序。插入快,检索慢。
顺序文件 (Sequential):记录按搜索码(Search Key)顺序存储。适合全文件扫描,但插入/删除维护成本高(需要移动记录或使用溢出块)。
多表聚簇 (Multitable Clustering):
定义:将不同关系(表)的相关记录存储在同一个块中。
例子:将
department记录和对应的instructor记录物理上存放在一起。优缺点:对涉及连接(Join)的查询极快;但对于仅查询单个关系的查询性能较差(因为读入了无关数据)。
2.4 其他存储
列式存储 (Column-Oriented):按属性(列)分别存储。
优点:适合分析型查询(OLAP),压缩率高,CPU 缓存友好。
缺点:重组元组成本高,不适合频繁事务(OLTP)。
数据字典 (Data Dictionary):存储元数据(表名、字段名、视图定义、用户信息等)。
3. 题型预测与例题 (Exam Types & Examples)
题型一:定长记录的删除操作 (Fixed-Length Record Deletion)
考点:理解如何处理删除后的空洞。
场景:PPT 第 12-14 页展示了
instructor表。
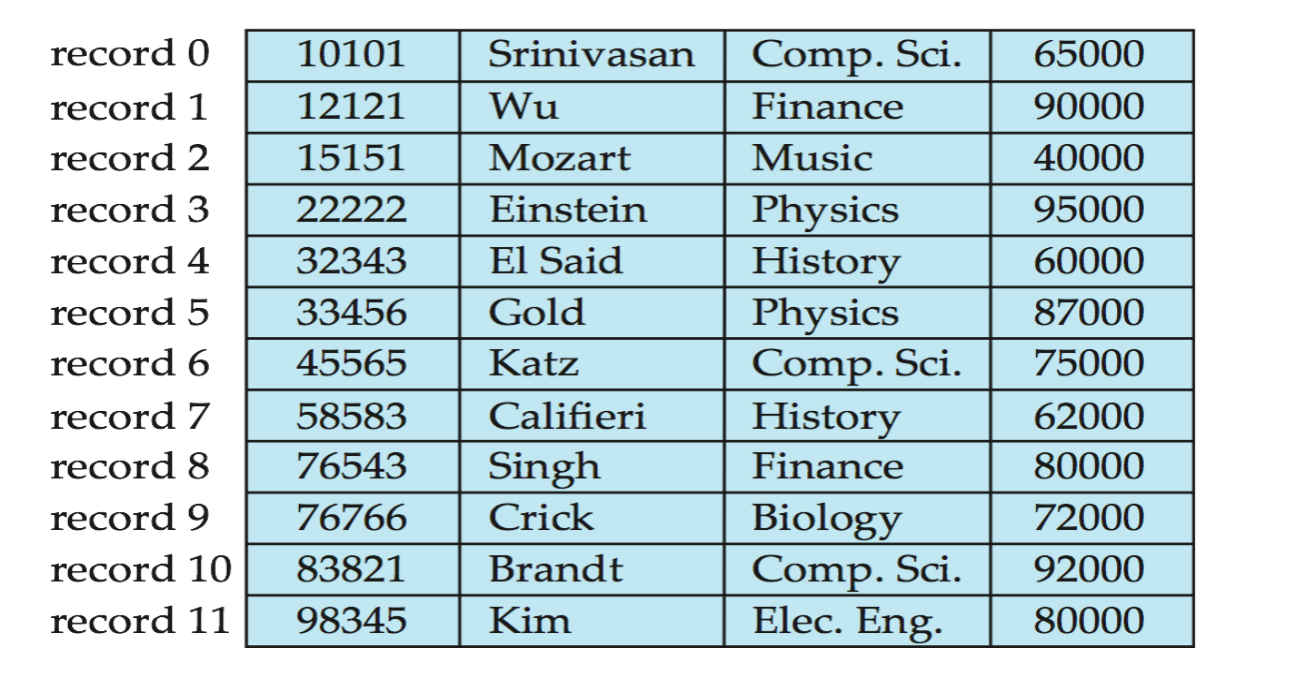
问题:假设我们删除了 record 3 (Einstein),如果要保持文件紧凑(Compacting),应该怎么做?
答案:
笨办法:移动后续所有记录 (Record 4-11) 往前挪一位(开销极大)。
聪明办法:移动最后一条记录。把 record 11 (Kim) 直接移动到 record 3 的位置。
题型二:分槽页结构 (Slotted Page Structure)
考点:画图或解释分槽页如何工作,特别是 Header 的作用。
问题:在变长记录中,如果我把一条记录从页面中间移动到页面底部以消除碎片,为什么不需要更新指向这条记录的外部索引指针?
答案:因为外部指针指向的是 Block Header 中的槽位 (Slot/Entry),而不是记录的实际物理地址。当记录移动时,我们只需要更新 Header 中对应槽位的
(location, size)信息,外部指针保持不变。
题型三:缓冲区替换策略 (Buffer Replacement)
考点:区分 LRU 和 MRU 的适用场景。
问题:假设我们要对两个大表进行嵌套循环连接(Nested Loop Join),Block 1 被读取后处理完毕,接下来系统需要空间。如果使用 LRU 策略会发生什么?
答案:
LRU 会把 Block 1 踢出(因为它是最早读入的)。
但在循环连接中,下一轮扫描马上又要读 Block 1。
结果:导致缓存抖动 (Thrashing)。
修正:这种场景下 MRU 更好,或者使用 Pinned 策略。
题型四:聚簇文件组织 (Clustering File Organization)
考点:判断何时使用聚簇。
场景:PPT 第 26-27 页。
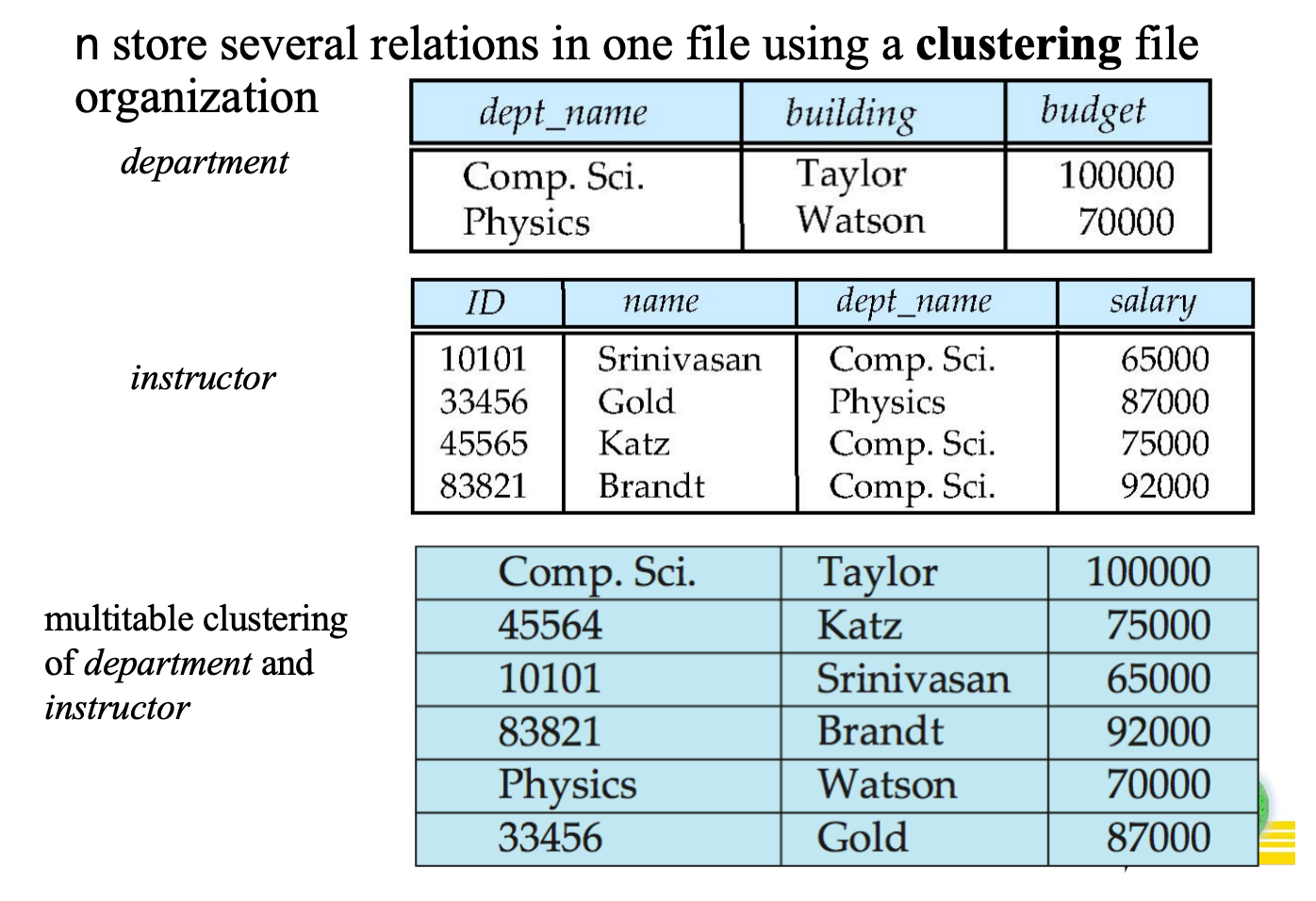
问题 1:如果系统中最频繁的查询是
SELECT * FROM instructor WHERE dept_name = 'Physics',使用聚簇组织有什么好处?- 答案:使用聚簇可以将 Physics 系的定义记录和所有物理系的 instructor 记录存在同一个(或相邻的)Block 中。这样只需要极少的 I/O 操作就能一次性把所有相关数据读出来。
问题 2:如果查询是
SELECT budget FROM department,聚簇好吗?- 答案:不好。因为为了读 department 的数据,不得不把混在一起的 instructor 数据也读进内存,浪费了带宽和缓存空间。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

