


最近读的论文实在太多了。一直没有功夫好好整理…终于今天闲了一点,于是抽空整理一下
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
本文来自快手的一篇技术报告。其核心思想就是通过修改clip机制,让高熵token能够保留梯度信息。
主要方法
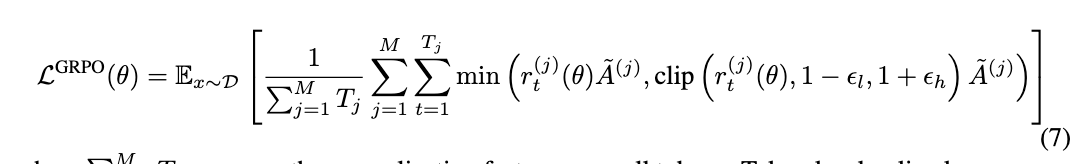
我们注意到,传统的GRPO没有办法在clip之后保留梯度信息。但是高熵token很容易被clip,这样就导致丢失了一部分很重要的梯度信息。
因此作者做了这样的一个创新:
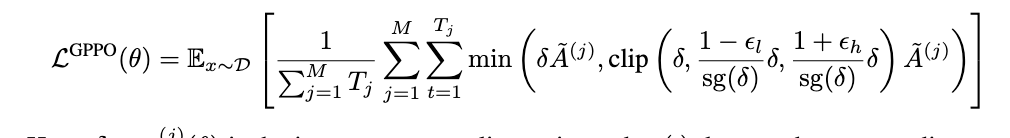
sg,即stop-gradient操作。会在反向传播的时候遇到的时候梯度清零。正向的时候返回sg(x)
= x。
因此,正向传播的时候结果不变,但是反向传播的时候可以融入梯度信息。这样就保留了高熵token的梯度。经过试验,比DAPO的clip-higher要强。
可以考虑复现这个方法,挺有价值的
DAPO
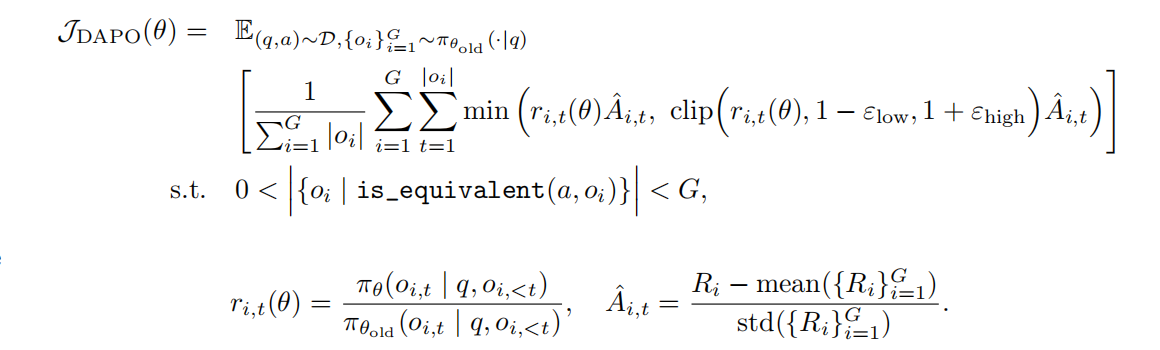
主要方法
有一些比较重要的trick需要理解
Clip-higher
引入非对称的clip,提出允许一定程度的探索。
Dynamic Sampling
有可能一个组的答案全是对的。那么需要丢弃一部分,直到生成的有错误的才可以。
token-level gradient loss

Overlong Reward Shaping
当响应长度超过预定义的最大值时,我们定义一个惩罚区间。在该区间内,响应越长,受到的惩罚越大。这种惩罚添加到原始基于规则的正确性奖励中,从而向模型发出避免过长响应的信号。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

