


Bradley–Terry and Multi-Objective Reward Modeling Are Complementary
要解决的问题
在OOD的问题中,存在严重的Reward-Hacking问题
方法论
作者设计了一个loss,将单目标的loss和多目标的loss拼在一起,最终实现了SOTA。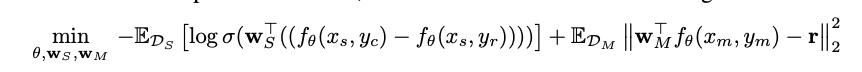
然后作者讲了一堆故事说单目标和多目标能互相辅助提升。
也没贴代码…不评价了
作者可能也知道自己没代码,不可复现,结论很weak,于是搞了一堆理论上的分析…懒得看了,感觉没什么用
RS-DPO- A Hybrid Rejection Sampling and Direct Preference Optimization Method for Alignment of Large Language Models
本文要解决什么问题
本文希望设计一种新的对齐方法,既能像PPO那样利用模型自身的输出(on-policy)进行学习,又能像DPO那样保持训练过程的简洁、高效和稳定
方法论
论文提出了RS-DPO训练框架,旨在利用Reject-Sampling中那些被拒绝掉的信息。说白了就是做错题。
整体框架如下:
1. 准备阶段:获得SFT模型和奖励模型
- 首先,通过监督微调(Supervised Fine-Tuning, SFT)得到一个基础的策略模型。
- 另外,准备一个已经训练好的奖励模型(Reward Model, RM),它将作为“评委”来为模型输出打分。
核心步骤:通过拒绝采样生成偏好数据 (PDGRS)
生成 (Generate):对于一个给定的提示(Prompt),让第一步得到的 SFT 模型自己生成
k个不同的回复(例如k=16)。评分 (Score):用奖励模型(RM)为这
k个回复逐一打分。配对与筛选 (Pair & Select):这是“拒绝采样”思想的体现。遍历所有可能的回复对(
y_i,y_j),计算它们之间的奖励差距(reward gap)。如果这个差距足够大(即大于一个预设的阈值η),就认为这是一个清晰、有价值的偏好对,并将得分高的作为“选择的”(chosen),得分低的作为“拒绝的”(rejected),存入一个新的合成偏好数据集中。
对齐阶段:使用DPO进行微调
- 最后,使用上一步生成的、高质量的、且完全来自模型自身的合成偏好数据集,通过DPO算法来微调SFT模型。
这个流程的巧妙之处在于,它通过一个离线的“数据准备”过程(步骤2),为DPO创造了最适合它的“养料”——反映了模型当前能力和倾向的偏好数据。
实验
实验设置:使用Llama-2-7B作为基础模型,在
Anthropic/HH-RLHF和WebGPT等数据集上进行对齐,并使用MT-Bench和AlpacaEval进行评估。对比方法:
RS-DPO与多种策略进行了对比,包括:标准的DPO(使用原始标注数据)。
PPO。
纯拒绝采样(只用最好的样本做SFT)。
其他变体,如“最好vs最差”、“最好vs随机”。
主要发现:
性能最优:在所有实验中,
RS-DPO的表现都稳定地优于所有其他基线方法,包括PPO、DPO和纯RS。“On-Policy”数据的重要性:实验证明,使用模型自身生成的回复来构建偏好对(即便是简单的“最好vs最差”策略),其效果也优于使用原始标注数据的标准DPO。这证实了让模型从“自己的错误”中学习是更有效的。
数据利用率高:
RS-DPO通过利用所有k个输出来构建大量的偏好对,显著优于只使用最好的一个样本的纯RS方法。对奖励模型的鲁棒性:实验还发现,PPO的性能对奖励模型的质量非常敏感,当换用一个较弱的奖励模型时,PPO的性能会大幅下降。相比之下,
RS-DPO的表现则稳定得多,展现出更好的鲁棒性。资源高效:相比于PPO,
RS-DPO将资源消耗巨大的采样过程放到了训练前离线进行,并且最终的DPO训练阶段非常高效,对计算资源的要求远低于PPO。
总结
本文主要是“对比”和On-policy算法的一个平衡。是高效利用数据,以及做错题的哲学思想的体现。
淘宝直播数字人LLM推理优化:模型蒸馏与路径压缩实践
这是一篇来自大淘宝技术的实践文章。并不是实际上的论文,但是也有可以借鉴的地方。
文章要解决的问题
如何在保证LLM高质量推理能力的同时,将其推理时间(RT)压缩到足以满足直播场景实时互动需求的水平。
方法论
我觉得这篇文章值得我们学习的不仅仅有它的方法, 还有它探寻的过程。
第一阶段:模型蒸馏 (把“大脑”变小)
目标:将
DeepSeek-R1的能力迁移到更小的模型上。尝试:团队设计了三种蒸馏方案,包括使用
Qwen作为基座蒸馏DeepSeek-R1的答案部分或完整输出,以及使用官方发布的DeepSeek-R1-Distill-Qwen作为基座进行蒸馏 。结论:实验证明,方案C,即以
DeepSeek-R1-Distill-Qwen-14B为基座,蒸馏DeepSeek-R1完整的思考过程(CoT),效果最好,比线上非蒸馏模型性能提升了8个百分点 。遇到的新问题:虽然性能达标了,但这个14B的蒸馏模型依然太慢,无法上线使用 。
第二阶段:推理路径压缩 (让“思考”更高效)
目标:在保持性能的同时,大幅缩短模型的输出长度和推理时间。
尝试1:复现 Kimi long2short DPO
方法:对那些输出过长的样本,让模型重新生成多次,然后将最短的正确答案作为“chosen”(正例),将最长的答案作为“rejected”(负例),进行DPO训练,教模型偏爱“简短的回答”。
结果:非常有效!平均推理时间缩短至4.24秒,最长响应时间从近12秒压缩到6.24秒,时间几乎减半 。
遇到的新问题:和Kimi论文中描述的一样,这种方法虽然缩短了路径,但导致了性能的轻微下降 (-1pt) 。
尝试2(本文核心创新):改良版DP-DPO (Dual-Preference DPO)
思想:
long2short DPO只考虑长度偏好,可能会把一个“虽然长但质量高”的答案当作负例,把“虽然短但质量差”的答案当作正例,从而导致性能下降。DP-DPO旨在同时优化两个目标:既要路径短,又要质量高。方法:在构建DPO偏好对时,不再只看长度。而是设计了一个加权融合分数:
其中,
是长度, 是由 DeepSeek-R1评判的质量分,α 和 β 是权重。用这个融合分数来决定哪个是“chosen”(最高分),哪个是“rejected”(最低分) 。结果:非常成功!DP-DPO在保持与
long2short DPO几乎相同压缩效果的同时,不仅没有降低性能,反而有小幅提升(+0.4pt),性能已经非常接近教师模型DeepSeek-R1。
第三阶段:解决DPO的泛化性问题
目标:提升DP-DPO模型在真实线上流量中的表现。
遇到的新问题:模型上线后发现,DPO虽然在验证集上表现优异,但在面对未见过的线上真实流量时,性能下降明显,泛化性变差了 。
解决方案:简单粗暴但有效——扩大DPO的训练数据规模。团队将用于DPO训练的数据量扩大了5倍 。
最终结果:
泛化后的DP-DPO模型在线上测试集上性能大幅提升(+2.3pt)。
在验证集上的性能甚至超越了教师模型
DeepSeek-R1(+1.8pt)。同时,依然保持了优秀的推理路径压缩效果。
评价
技术路线图:
验证优秀大模型 -> 模型蒸馏 -> 发现速度瓶颈 -> 路径压缩 (long2short DPO) -> 发现性能瓶颈 -> 改良版路径压缩 (DP-DPO) -> 发现泛化瓶颈 -> 扩大数据规模 -> 最终成功。核心创新点:提出了DP-DPO(双偏好DPO)方法,通过构建一个(长度+质量)的联合偏好,巧妙地解决了“既要…又要…”的多目标优化问题,在压缩推理路径的同时还能提升模型性能。
工程价值:这篇文章提供的不仅是一个算法,更是一套宝贵的工程实践方法论。它证明了通过蒸馏 + 路径压缩 + 泛化增强,可以在不牺牲甚至提升模型能力的前提下,实现显著的推理优化,这对于推动大模型在低延迟场景下的落地应用具有重要的参考价值。
其实我觉得这种思想,基本已经等价于一个用于平衡长度和质量的GRPO了。DPO用的数据都是模型自己产出的。评价方法是rule-based的….
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

