


由于前两天一直在写verl和SFT的代码,导致笔记中断了几天,现在开始补
Think Clearly: Improving Reasoning via Redundant Token Pruning
要解决的问题
OverThinking, Useless Thinking
方法论
作者发现,当模型结束思考并准备给出答案时(例如生成
</think>
这样的特殊标记时),它会自然地将注意力集中在那些对最终结论至关重要的推理步骤上
直接删除单个分数低的token可能会破坏推理的连贯性。作者观察到,冗余信息往往是以“块”或“步骤”的形式存在的(比如一整段错误的尝试)(标记,可能对我有用)
作者做了两个方法来解决这个问题:
self-summarization:在推理过程中,并非等到自然结束,而是周期性地(例如每生成200个token)“打断”模型,并插入一段特殊的指令,强制它进行“中场总结”
。这个指令大致是:“时间到了,根据我已经尝试的思路,我应该停止思考,用一句话总结一下,然后输出<\think>
Step-aware Eviction:
- 步骤切分:首先,使用一些预定义的关键词(如 “Wait”,
“Alternatively”, “First”, “Thus” 等)将整个推理过程切分成多个逻辑步骤
。
计算步骤得分:然后,将每个步骤内所有token的重要性得分进行平均,得到每个推理步骤的整体“冗余分” 。
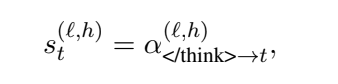
这里,他们评估重要性得分的方法,就是看在输出<\think>token的时候,对于这个token的注意力权重分层剪枝:在给定的剪枝预算(比如要删除k个token)下,优先从最冗余的步骤(即得分最低的步骤)开始删除token。在每个被选中的步骤内部,再具体删除那些token级别得分最低的token 。
恢复生成:完成剪枝后,移除之前插入的“总结指令”,让模型在更“干净”的上下文中继续进行后续的推理 。
评价
这篇文章的motivation很不错,但是个人觉得这个方法拿来生产数据挺好的,但是部署到模型上就有点夸张了。因为你终归还是要花资源花时间去推理的。只不过在输出的时候把它删掉而已。那么这种方法实际只是输出的结果比较好看罢了。
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
要解决的问题
主要是PRM的信用分配问题和Reward Hacking问题
传统的信用分配 (Summation-form):在标准RL中,一个动作的“价值”(即它的长期回报)被定义为未来所有奖励的累加和(通常带衰减) 。
问题所在: 这种“求和”的形式,意味着只要未来有一个步骤能获得极高的奖励,那么通往这个步骤的所有先前动作的价值都会被抬高 。这会诱导LLM去“破解”那些能产生高分数的特定步骤(比如只“思考”而不解决问题),而不是完整地、正确地解决问题,最终导致训练崩溃 。
方法论
作者提出了一个名为PURE的信用分配方法,作者把一个动作的长期价值定义为未来所有步骤的最小值。
不过这么做似乎打破了贝尔曼方程,使得
为此作者进行了一个trick
通过上面两个公式,就可以把这个方法应用到标准的强化学习流程了
评价
很有创意的想法。我之前也冒出过一个想法,就是,从motivation的角度来说,把gamma降低不是能达到一样的效果吗?
后面找到作者本人,作者这样回复的:
plain text 调低gamma可以预料不利于scale length,如果token数上10k的话,首token几乎是收不到最终reward回传的信号的
RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback
本篇主要解决的是多模态的问题,但是提出的DDPO方法很有参考性
密集直接偏好优化 (Dense Direct Preference Optimization,
DDPO)
背景:直接偏好优化(DPO)是一种比传统RLHF更简单、更稳定的方法,它跳过了训练奖励模型的步骤,直接在偏好数据上优化策略模型 。
本文的改进 (DDPO):标准的DPO同样是为整个回复的偏好设计的 。为了利用上述的细粒度修正数据,作者提出了DDPO。其核心思想是在计算回复的得分时,给予被修正过的片段更高的权重 。
DDPO的核心思想:DDPO认为,在一个经过人类修正的回复中,被修正过的部分(即原始幻觉部分) 比那些未被改动的部分,更直接地揭示了人类对于幻觉的判断,因此应该在学习中获得更强的关注和反馈 。它要解决的问题是:如何让模型在优化时,重点关注并修正那些犯了错的片段,而不是在整个句子上平均用力
具体公式 :
(权重超参数):这是一个大于1的系数 。从公式中可以看到,它被乘在了被修正片段 的对数似然总和上。这意味着,这些片段对最终总得分的贡献被放大了 γ倍。这使得模型在反向传播计算梯度时,会收到一个更强的信号,促使其重点学习如何生成正确的内容来替代原始的幻觉内容 。N (归一化因子):
N被定义为。这是一个加权后的总token数。设置这个分母的目的是为了进行归一化,防止模型仅仅因为生成更长的回复而获得更高的分数 。它确保了得分的计算是公平的 效果:通过这种方式,模型在学习时会更“用力”地去修正那些产生幻觉的部分,使得人类的细粒度反馈能够被更有效地利用 。
评价
DDPO这个算法的思想,实际可以看作是一种
Self-Generated Critiques Boost Reward Modeling for Language Models
这篇论文试图解决什么问题?
标准的奖励模型是RLHF(从人类反馈中强化学习)流程的心脏,但它存在一些根本性问题:
缺乏可解释性(Black Box):标准的奖励模型在读取一个回复后,只会输出一个单一的、冷冰冰的数字(例如0.87分),但并不会解释为什么它给出了这个分数 。这使得我们很难理解和调试模型的偏好。
效率低下且易被“攻击”:由于仅仅输出一个分数,模型没有充分利用其强大的语言建模能力 。这导致它需要大量数据才能学好,并且容易出现“奖励破解”(Reward Hacking)问题,即模型找到捷径来获得高分,而不是真正生成高质量的回复 。
与“LLM即评委”范式的脱节:另一个流行的范式是直接让一个强大的LLM(如GPT-4)来写一段评语(critique)并打分 。这种方式可解释性强,但其输出的离散分数(如8/10分)难以直接用于RLHF中需要连续奖励信号的优化算法(如PPO)。
因此,本文的核心问题是:我们能否将“LLM即评委”的可解释性(生成评语)与传统奖励模型的连续分数优化能力结合起来,从而创造出一个更强大、更可靠、更高效的奖励模型?
方法论
Critic-RM
框架通过一个精巧的两阶段流程,让模型学会“边批判边打分”:
阶段一:高质量评语的生成与筛选
这个阶段的目标是为现有的偏好数据(即“选择A”和“拒绝B”)自动附上高质量的评语。
生成候选评语:首先,让基础LLM模型(例如Llama3.1-70B)自己充当“评委”,为“选择A”和“拒绝B”的回复分别生成多条(例如10条)候选评语,并为每条评语附上一个临时的离散分数(1-10分) 。
实例级过滤(去伪存真):检查模型自己生成的临时分数是否与人类的原始偏好(A优于B)一致。具体来说,计算A回复所有评语的平均分,和B回复所有评语的平均分。如果A的平均分确实高于B,那么这个数据点就被认为是“可靠的”,予以保留;反之,则被过滤掉 。这一步极大地减少了模型“胡言乱语”带来的噪音。
质量感知提炼(精益求精):对于通过了上一步筛选的评语,进一步提升其质量。论文提出了两种策略:
摘要式提炼(Summarization):让模型阅读自己为某个回复生成的所有评语,然后写一个“元评语”(meta-critique)来总结其中的核心观点,去粗取精 。
排序式提炼(Ranking):让模型再次评估自己生成的评语,并给这些评语打分,然后只保留质量最高的前K个(例如2个)评语 。
阶段二:评语生成与奖励建模的联合学习
这个阶段的目标是训练一个既能生成高质量评语,又能给出准确奖励分数的统一模型。
挑战:评语生成(语言建模任务)和奖励预测(回归任务)的学习目标存在冲突。前者需要多样化的数据来学习,而后者非常容易过拟合 。
解决方案:动态权重调度:论文设计了一个巧妙的训练策略。在训练初期,模型主要学习生成评语(
l_c损失权重高);随着训练的进行,权重逐渐转移,在训练的最后阶段,模型主要学习预测奖励分数(l_r损失权重高) 。这样既避免了奖励模型过早过拟合,又保证了模型充分学习到了评语的生成能力。
总结
创新点主要在阶段2,这个动态权重的调度方法值得学习。本文可以看做是GenRM的一个小的延伸,一个可靠落地的数据处理。
The Lessons of Developing Process Reward Models in Mathematical Reasoning
这篇文章的目的
这篇论文的核心目标是解决在开发过程奖励模型(Process Reward Models, PRM) 时遇到的两大核心挑战:不可靠的训练数据和有偏见的评估方法。
挑战1:如何获得高质量的训练数据?
人类标注:效果最好,但极其昂贵和耗时。
自动化方法:为了节约成本,社区普遍采用一种叫做蒙特卡洛(Monte Carlo, MC)估计的方法来自动生成标签。简单来说,就是从某一个步骤开始,让模型继续往下生成多次,看最终能得出正确答案的概率有多大,以此来判断当前步骤的“好坏”。
挑战2:如何科学地评估PRM的好坏?
- Best-of-N (BoN) 评估:这是目前最主流的评估方法。具体做法是让一个策略模型生成N个候选答案,然后用待评估的PRM给这N个答案的完整推理过程打分,选出得分最高的那个,看这个答案是否正确。
作者团队在实践中发现,上述的自动化数据构建方法(MC估计)和评估方法(BoN)都存在严重问题,导致训练出的PRM并不可靠。
本文的核心观点
这篇论文的核心贡献在于揭示了两个深刻的“教训”,并用大量实验数据进行了佐证。
教训一:蒙特卡洛(MC)估计法是“有毒”的
论文通过实验和分析指出,广泛使用的MC估计法来自动标注训练数据,其效果远不如“LLM作评委”或人类标注 。
根本缺陷:MC估计混淆了PRM和价值模型(Value Model) 的概念。
一个真正的PRM应该是一个确定性的评估器,只判断 当前步骤本身是否正确。
而MC估计实际上是在评估从当前步骤出发,未来有多大概率能成功。这本质上是在训练一个价值模型。
带来的问题:这种方法非常依赖后续补全模型的性能,会导致大量的标注噪声。例如:
一个错误的步骤,后续模型可能“歪打正着”蒙对了正确答案,导致错误步骤被标记为“正确”。
一个正确的步骤,后续模型可能自己犯了错,导致正确步骤被标记为“错误”。
实验证据:如Table 4所示,尽管使用了海量数据,通过MC估计训练出的PRM在识别具体步骤错误的能力上(PROCESSBENCH F1分数)远远落后于使用人类标注数据训练的模型 。
教训二:单独使用Best-of-N(BoN)评估法是“有偏见的”
论文指出,只用BoN来评估和优化PRM,会误导模型的学习方向,使其偏离“过程监督”的初衷。
BoN与PRM的目标不一致:BoN只关心最终答案是否正确。然而,现在的策略模型经常能通过错误的、不严谨的过程,侥幸得到正确的答案。BoN会奖励这种情况,而一个好的PRM本应惩罚这种错误的推理过程。
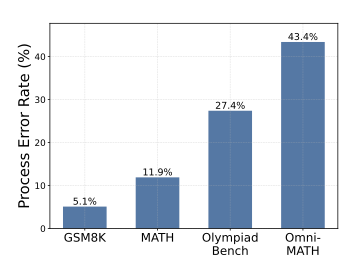
如图所示,这个图描述了LLM产生正确答案但是错误步骤的比率。导致PRM能力退化,分数虚高:为了在BoN上获得高分,PRM会学会“容忍”那些“答案正确但过程错误”的解法,这导致其BoN分数被人为抬高(inflated),但其真正的过程校验能力却很弱 。
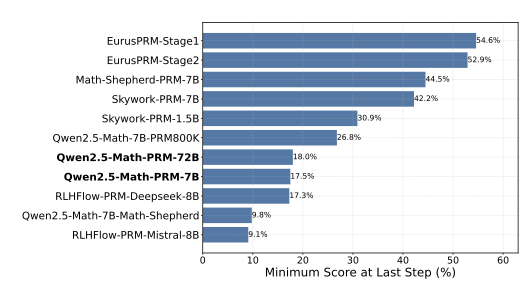
从“过程监督”退化为“结果监督”:最致命的是,为了优化BoN,PRM会逐渐把注意力从中间步骤转移到最后一步(即答案)上。论文通过下图发现,很多现有的开源PRMs,其给出的最低分(决定性的“瓶颈分”)有超过40%的情况都出现在最后一步上 。这意味着这些PRM实际上已经退化成了结果奖励模型(ORM),失去了过程监督的意义 。
解决办法
文章提出了Qwen2.5-Math-PRM-7B和72B模型
并提倡将BoN和PROCESSBENCH这种步骤级别的评估结合起来,进行更全面的衡量。
数据层面,本文提出共识过滤机制,先用MC估计法生成初步的步骤标签,再用一个强大的LLM(如Qwen2.5-72B-Instruct)作为评委去检查同一个推理过程。
只保留那些MC估计和LLM评委都认为是错误,并且错误位置也一致的数据点
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

