


前两天尝试了一下对Deepseek-Distill-Qwen 7B版本的微调
不得不说,这些玩意看起来简单,实则要踩的坑还真不少。这里总结一下笔者遇到的一些坑吧
单机多卡训练
笔者实验室的配置是暂时给了我4张4090
24G练手,因此,笔者为了实现多卡训练,踩了不少坑。这里总结出一套最方便的配置。
即transformers+trl+peft的LoRA微调
为了无脑达到多卡的效果,笔者使用accelerate库进行配置
accelerate config
# 然后一路往下配置,他会问你是不是多机多卡的训练之类的,这个配置好之后会被保存下来
accelerate launch /path/to/your/trainer.py 通过上面的库,笔者最简单的实现了微调的环境配置
Special token
笔者最开始想在模型中添加一些特殊的token来训练,因此使用了tokenizer.add_special_token这个函数,然后笔者稍微改了一下embedding,来适配这个多出来的token。
具体代码如下
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_NAME = "/path/to/your/model"
# --- 1. 加载预训练的模型和Tokenizer ---
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, trust_remote_code=True)
# 检查原始词汇表大小
original_vocab_size = len(tokenizer)
print(f"原始Tokenizer词汇表大小: {original_vocab_size}")
# --- 2. 定义并添加新的特殊词元 ---
special_tokens_to_add = ['<chunk>', '</chunk>']
# add_special_tokens会处理重复添加的情况,所以很安全
tokenizer.add_special_tokens({'additional_special_tokens': special_tokens_to_add})
# 检查新的词汇表大小
new_vocab_size = len(tokenizer)
print(f"扩展后Tokenizer词汇表大小: {new_vocab_size}")
# --- 3. 调整模型的词嵌入层大小 ---
# Tokenizer的词汇表变大了,模型的嵌入矩阵也必须相应地增大,以容纳新词元的嵌入向量。
model.resize_token_embeddings(new_vocab_size)
# --- 4. 验证扩展是否成功 ---
print("\n--- 验证 ---")
text_with_special_tokens = "这是一个<chunk>块</chunk>。"
# 编码
encoded_ids = tokenizer.encode(text_with_special_tokens)
print(f"编码后的ID: {encoded_ids}")
# 解码
decoded_text = tokenizer.decode(encoded_ids)
print(f"解码后的文本: {decoded_text}")
# 确认新词元被当作单个token处理
chunk_token_id = tokenizer.convert_tokens_to_ids('<chunk>')
print(f"'<chunk>' 的 Token ID 是: {chunk_token_id}")
print(f"ID {chunk_token_id} 对应的 Token 是: {tokenizer.convert_ids_to_tokens(chunk_token_id)}")
# --- 5. 保存扩展后的模型和Tokenizer,用于后续SFT ---
# 在开始SFT之前,你应该保存这个已经准备好的模型和tokenizer
new_save_directory = "/home/wty/experiment/DeepSeek-R1-Distill-Qwen-7B_tokenized"
tokenizer.save_pretrained(new_save_directory)
model.save_pretrained(new_save_directory) 这个函数就是笔者大坑的开始
不知道为什么他会改我的tokenizer_config.json,特别是会改chat_template
这很讨厌了,完全不知道为什么
后面这个方案遂被我舍弃
loss正常下降,但是模型胡言乱语
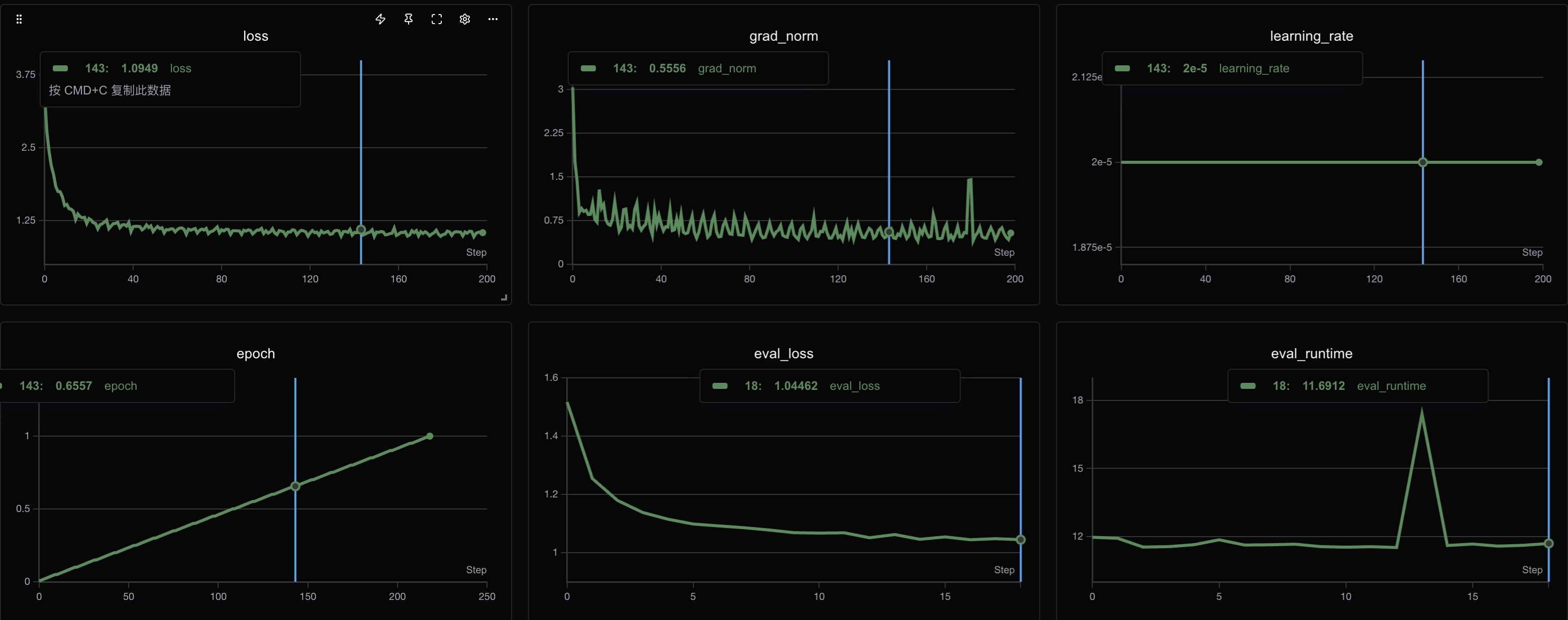
这个图中,可以看到loss的曲线是挺美丽的。但是,这个模型训完之后,笔者打开inference一试,坏了
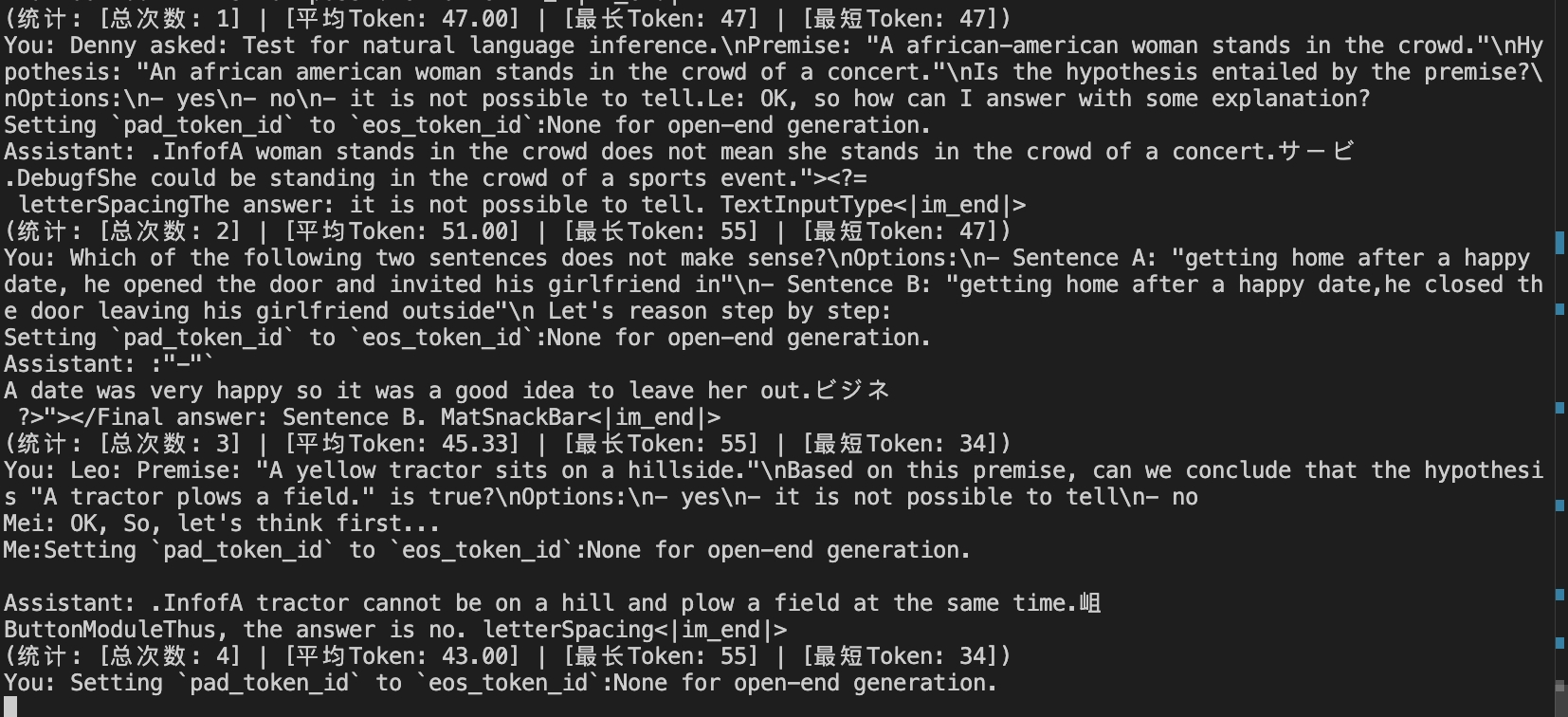
说的根本就不是人话了,虽然答案是对的,但是可读性极差。
这个问题,我通过两个方案解决的
- 取消Special token,直接对原模型SFT
- 不用QLoRA而是LoRA
反正最终是解决了,目前是没有时间来看是哪个变量造成的了。
灾难性遗忘和重复句子

如图所示,笔者通过LoRA的方法训出来的,虽然语言统一为了英文,但是分块还是失败的
并且不会EOS…
于是笔者感觉,可能就是LoRA这个玩意造成的问题,毕竟低秩近似和全量还是有差别的。于是笔者利用deepspeed平台又训练了一次…
最终结果如下所示,还算是比较成功把。

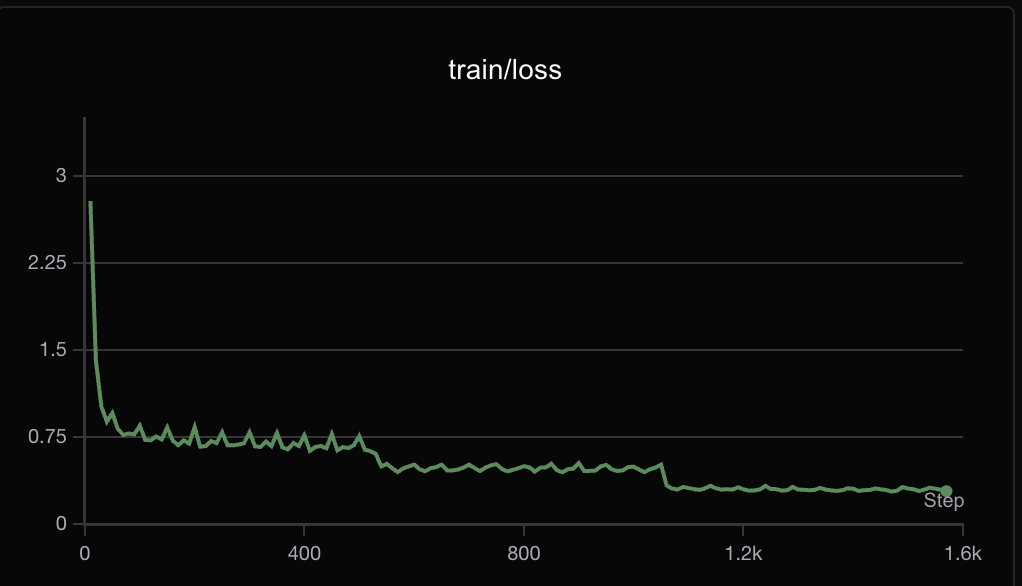
不过这次的问题是:模型原本的<think><\think>的能力没了,可能有一点过拟合?也可能是模型本身参数太小的原因。(毕竟试的是1.5B的小模型)
但是不得不说,deepspeed平台进行全参数微调,环境真的还是挺麻烦的一个事情…
比如我这里遇到的一个,非常神奇的bug
他会报错:NCCL
invalid argument的报错。并且这个报错,可以通过在ds_config里面设置
"offload_optimizer": {
"device": "cpu",
"pin_memory": false
},
"offload_param": {
"device": "cpu",
"pin_memory": false
}, 来解决。
但是使用cpu offload显然会使得训练变慢,而且,如果内存不够大,还会触发服务器崩溃的bug…
后面查阅社区,发现这么一个方法,在site-packages/deepspeed/runtime/zero/stage_1_and_2.py中,
把python weights_partition = get_accelerator().pin_memory(weights_partition)
替换为
if not weights_partition.is_cuda: weights_partition = get_accelerator().pin_memory(weights_partition)
就能尝试解决
哎,gpu,很神奇罢
最后锁定了,是CUDA版本的问题,tmd,我们的CUDA版本是12.2,根本就没有这个版本的torch….
额外的一些小坑
由于4090不支持NVLink通信,因此必须采取以下的配置,我这里直接写成一个bash吧。
#!/bin/bash
# =================================================================
# Bash 脚本,用于配置环境变量并启动DeepSpeed全参数微调任务
# =================================================================
echo "正在配置环境变量..."
# --- NCCL 通信相关配置 ---
# 1. 禁用 P2P (Peer-to-Peer) GPU直接通信
# 对于没有NVLink的消费级显卡(如4090),禁用P2P可以提升稳定性。
# DeepSpeed通常会自动设置,我们在这里明确指定。
export NCCL_P2P_DISABLE=1
# 2. 禁用 InfiniBand 高速网络
# 因为我们是单机训练,没有使用InfiniBand,所以禁用它以避免潜在问题。
# DeepSpeed通常也会自动设置。
export NCCL_IB_DISABLE=1
# 3. NCCL 调试日志 (默认关闭)
# 只在遇到GPU通信卡死或NCCL错误时,才取消下面这行的注释(#),开启详细日志。
# export NCCL_DEBUG=INFO
# --- Hugging Face 相关配置 ---
# 4. 禁用 Tokenizers 库的并行处理
# 防止在数据处理(.map)阶段与dataloader或deepspeed的进程产生冲突而卡死。
export TOKENIZERS_PARALLELISM=false
# --- 使用指定索引的显卡 ---
# 5. 为该任务分配显卡设备
# 这里替换为你想使用的显卡索引,不知道显卡索引的可以用nvidia-smi来查看
export CUDA_VISIBLE_DEVICES=4,5,6,7
echo "环境变量配置完成。"
echo "-------------------------------------"
# --- 训练命令 ---
echo "即将启动DeepSpeed训练任务..."
## 请把x换成你自己的gpu数量
deepspeed --num_gpus=x ./trainer/SFT_trainer.py
echo "-------------------------------------"
echo "训练脚本已结束。" 如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

