


Pre-Trained Policy Discriminators are General Reward Models
文章要解决的问题
这篇论文旨在解决当前大型语言模型(LLM)在通过强化学习(RL)进行后期训练时,其核心组件——奖励模型(Reward Model, RM)——所面临的几个根本性挑战:
可扩展性问题 (Scalability):传统的奖励模型依赖于大量高质量的人工标注偏好数据(即“哪个回答更好”)。获取这种数据的成本非常高昂,规模也难以扩大 。
泛化能力有限 (Generalization):基于主观人类偏好训练出的奖励模型,往往难以泛化到训练数据分布之外的场景 。这使得模型容易找到奖励系统的漏洞并进行“奖励作弊”(Reward Hacking),即模型学会了如何获得高分,而不是真正地完成任务 。
缺乏统一的、根本性的优化目标:当前的奖励模型训练方法通常是针对特定的人类标准(如“无害性”),缺乏一个像“下一个词元预测”(Next Token Prediction)那样统一、普适且与具体标准无关的预训练目标 。这启发作者去寻找一个更底层的、可扩展的奖励模型预训练范式。
方法论
本文的核心观点:不再将奖励模型看作是绝对质量的评估器,而是将其重新定义为一个“策略判别器”(Policy Discriminator)。其核心思想是,奖励信号应该量化的是“当前模型策略”与“理想目标策略”之间的差异 。一个策略如果与目标策略更“相似”,就应该获得更高的奖励 。这个想法为建立一个可扩展的、与具体标准无关的预训练框架(POLAR)奠定了基础。
核心目标:训练一个Reward model来提供好的激励信号
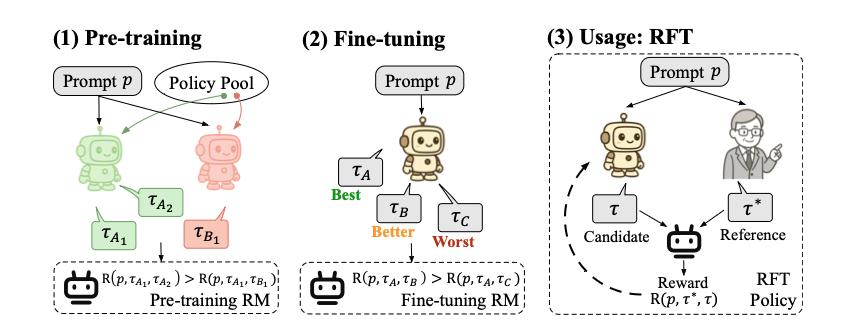
作者分为三个阶段来训练这个奖励模型。
阶段1:预训练 (Pre-training)
过程描述:
从一个包含多种不同模型(如图中的绿色和红色机器人)的“策略池”中,随机挑选两个不同的策略。
给定一个提示
p,让第一个策略(绿色机器人)生成两个不同的回答,即和 。 同时,让第二个策略(红色机器人)也对同一个提示
p生成一个回答。
学习目标:
训练一个“预训练奖励模型”(Pre-training RM),使其满足以下条件:
通俗解释:这个目标是教会奖励模型一个基本但核心的能力——识别策略的一致性。模型需要认识到,来自同一个策略的两个不同回答(
, )之间的“差异度”要小于一个来自自身策略的回答( )和另一个来自不同策略的回答( )之间的差异度。换句话说,它学会了给源自同一策略的回答对打出更高的“相似分”或“一致性分” 。这个过程是与具体标准无关的(criterion-agnostic),因为它不关心回答的好坏,只关心回答的“出处” 。
阶段2:微调 (Fine-tuning)
过程描述:
使用一个策略模型(图中的米色机器人),针对一个提示
p生成三个不同的回答。人类标注员对这三个回答进行排序,标记出哪个是“最好 (Best)”,哪个是“较好 (Better)”,哪个是“最差 (Worst)”。图中将这三个回答分别表示为
学习目标:
- 在预训练模型的基础上进行微调,使其满足人类定义的标准
。目标函数为:
- 通俗解释:这个阶段将模型在预训练中学到的通用“判别能力”与人类的价值观对齐。虽然三个回答可能来自同一个模型,但人类的排序行为隐含地定义了什么是“好”的标准
。模型学习到,以最好的回答
为参考时,较好的回答 应该比最差的回答 获得更高的奖励分数。
- 在预训练模型的基础上进行微调,使其满足人类定义的标准
。目标函数为:
阶段3:使用:强化微调 (Usage: RFT)
过程描述:
在实际应用中,我们有一个需要优化的策略模型(米色机器人)和一个代表人类期望的高质量“参考回答”
(由人类专家或更强的模型提供,如图中的人类形象)。 策略模型针对提示
生成一个“候选回答” 。 经过微调的奖励模型(Fine-tuning RM)会同时评估“候选回答” τ 和“参考回答”
,并输出一个奖励分数 。这个分数衡量了候选回答与参考回答的相似或一致程度。 这个奖励信号被反馈给策略模型,通过强化学习算法来更新和优化模型,使其生成的回答越来越接近参考回答的质量。
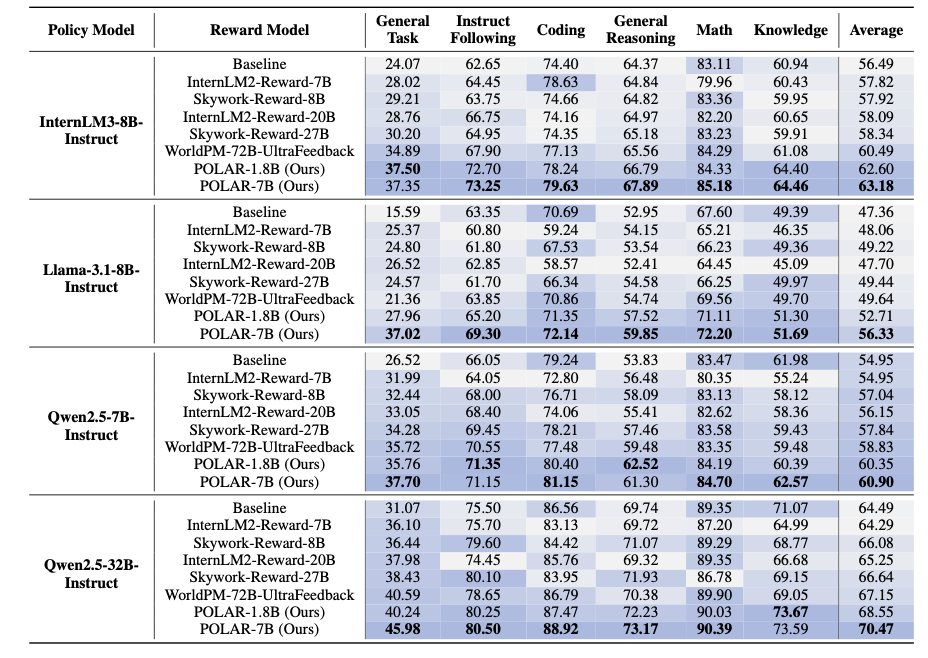
这个方法虽然很平凡,但是实现效果却很好
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

