


写这篇报告的动机主要是昨天晚上看的两篇文章,让我挺有感触。对于CoT和Reasoning本身也有了一些深刻的理解。在此简单记录。
RL的本质:熵减
首先我们不得不承认一个事实:当前的RL方法,无法教会模型任何新的能力。我们只能使得它更加偏好以固定的格式输出正确答案。因此,有学者指出RL的本质是一个distribution shift。
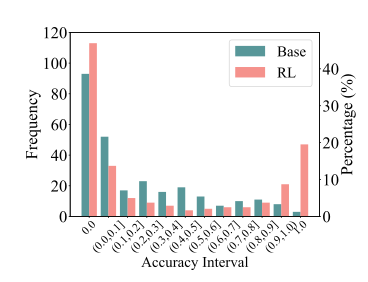
从上图中我们可以看出,本质上RL就是强化对于简单问题的自信,对于难题他仍然无法解出。
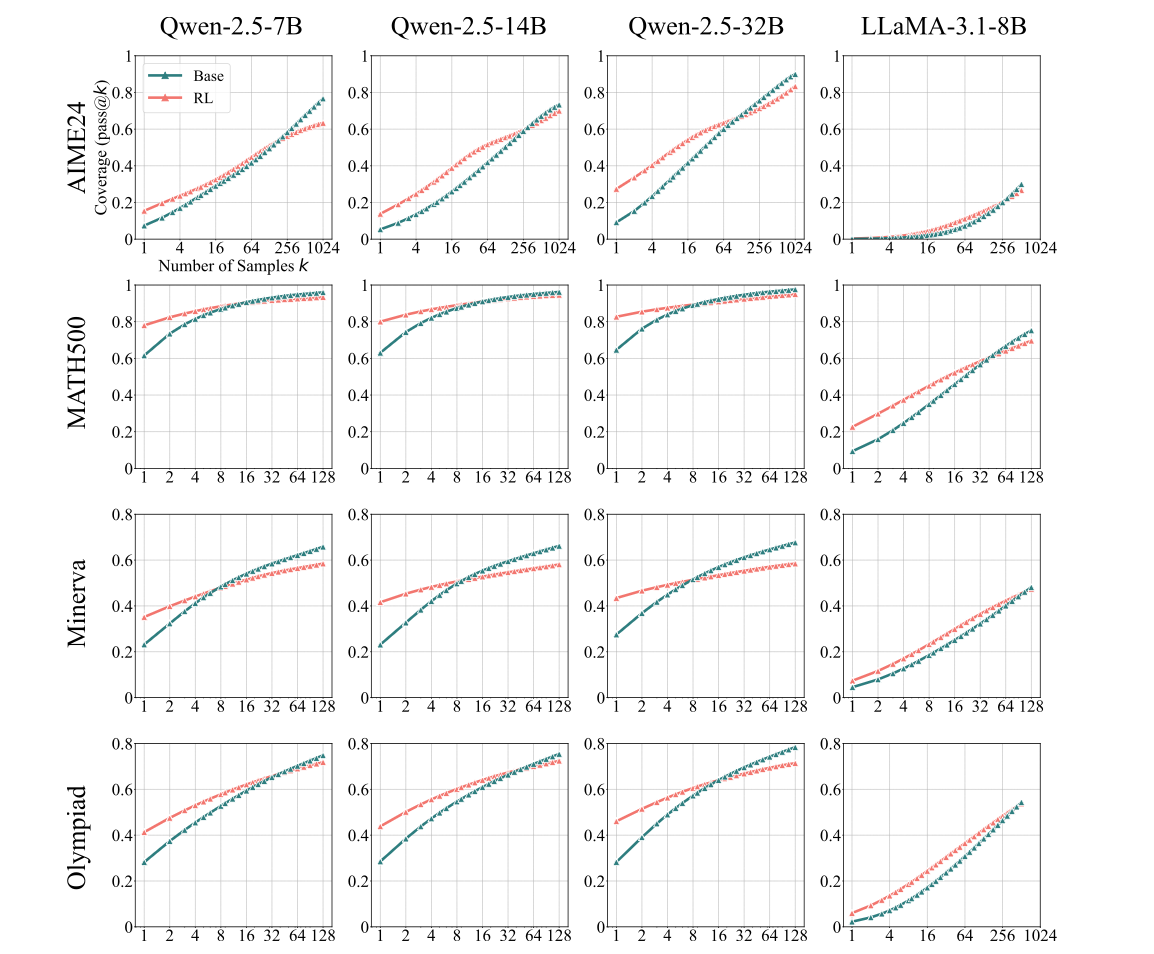
使用pass@K指标,我们可以清楚的看到,随着K的增大,经过RL训练的模型的解题能力往往低于Base模型。这意味着,Base模型往往具有相比于RL更强的解题能力,但是它的所有答案中,正确答案的熵可能是比较高的。即Base模型具有相当强的答案的异质性和反集中性。
那么RL做了什么呢?本质就是让模型更加偏好输出那些正确的答案。我们把他们的熵降下来,这样模型就更容易在一条回复中直接得到正确答案。
具体来说就是下面这个图
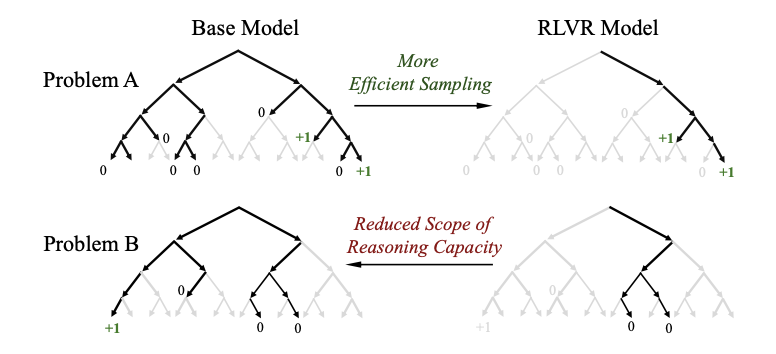
从这张图来理解这个原因,就会好理解很多
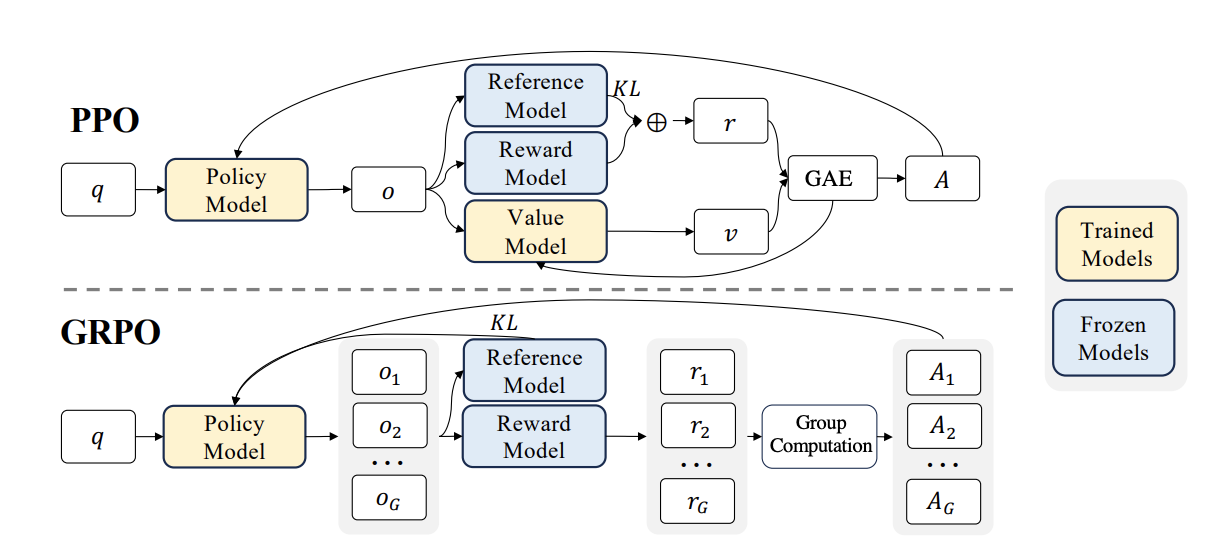
我们可以看到,现有的RL的本质,是从Policy Model,也就是我们的Base
model采样,得到了相应的结果之后,根据rule-based的方法,我们得到答案中的reward。但是问题来了,如果Base
model能力很弱,采样出的一组答案中完全没有正确答案,那么模型也就不知道哪个好了。因此,现有的RL是强化LLM,让它更偏好输出正确答案的一个方法。
那么如何改进呢?个人认为,PRM才是正确的道路。我们要让RL能够对每个步骤,每个过程打分。让模型学习到这个步骤在推理过程中起到什么样的关联和作用。
或者,可以改进算法,让它能够和环境在线的交互。这样就可以更多的引入外部知识。也可以提高模型的能力。
目前的Reasoning的本质:格式化的输出
在明确了RL的本质之后,一个对于现在Reasoning的本质的答案也就水落石出了:目前的Reasoning只不过是让模型懂得,如何“看起来有道理”的输出。模型从一开始就知道答案可能是什么。
R1-Zero的纯RL探索也证明了这一点,如果不加任何的SFT和格式化的内容,那么RL就变成了,如何偏好正确答案的输出,即降低了最后正确答案的熵,减少输出的异质性罢了。
如何提升Reasoning能力?
如果Reasoning的目的就是为了让模型的输出看起来更加有道理。那么我觉得可以更加严格的限制模型的输出格式。尤其是数学上的话,可以按照这样的一个模式来限制格式:
- 初始条件
- 引理和已知的定理
- 推导步骤x,要说明用到的定理和条件
- 得到结果
- 分析结果
如果Reasoning的目的是为了真实的提高模型的性能。那么引入在线的环境交互(类似人工Distill)是不可或缺的。就此来说,GenRm的道路可能也是对的。因为人工成本实在是过于昂贵了。
Reference
[1] Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Yue, Y., Song, S., & Huang, G. (2025). Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? arXiv. https://doi.org/10.48550/arXiv.2504.13837
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

