


Learning to Reason under Off-Policy Guidance
要解决的问题
通过混合数据的方式,将现在模型中普遍使用的on-policy方法和off-policy数据混合。在on-policy的算法下,加强模型的off-policy能力
方法论

通过这个方法,将二者的优化目标统一。
对于off
policy的算法,不可避免的会用到重要性采样。因此,作者为了避免梯度中对于小概率事件以及高概率事件的忽略性,使用了一个额外的函数替代off-policy中的CLIP。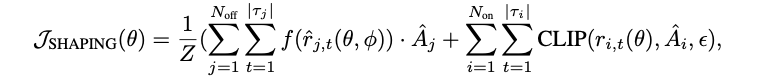
最终变成这样
Principled Data Selection for Alignment: The Hidden Risks of Difficult Examples
文章解决的问题
这篇论文主要挑战并试图解决在大型语言模型(LLM)对齐(alignment)阶段一个被普遍忽视的问题:并非所有干净、高质量的偏好数据都是有益的,其中“过难”的样本实际上会损害模型的对齐效果。
即:
- 偏好数据本身存在难度差异。
过难的样本会损害对齐效果。
样本的“难易”是相对于模型能力而言的,更大的模型能消化更难的样本。
方法论
将数据集划分成两个部分,用DPO训练一个模型。后一半的数据集用来计算每个样本的DPO损失,据此可以看出模型对于问题的理解能力,即问题对于模型来说有多”难“。
Make Every Penny Count: Difficulty-Adaptive Self-Consistency for Cost-Efficient Reasoning
论文要解决的问题
普通的SC方法过于浪费计算量,ASC和ESC方法能够降低成本,但是没有利用先验的难度信息。应该根据问题的难度来调整SC的采样数量。
方法论
本文提出了一种名为DSC的方法。首先利用一个强大的模型对问题打分。然后根据打分分为简单和困难两种难度,最后,为不同难度的问题分配不同的SC长度。很平凡的想法- -
Adaption-of-Thought: Learning Question Difficulty Improves Large Language Models for Reasoning
论文要解决的问题
根据问题的难度,自适应的进行推理长度的限制。
方法论
这篇工作的想法也非常的平凡。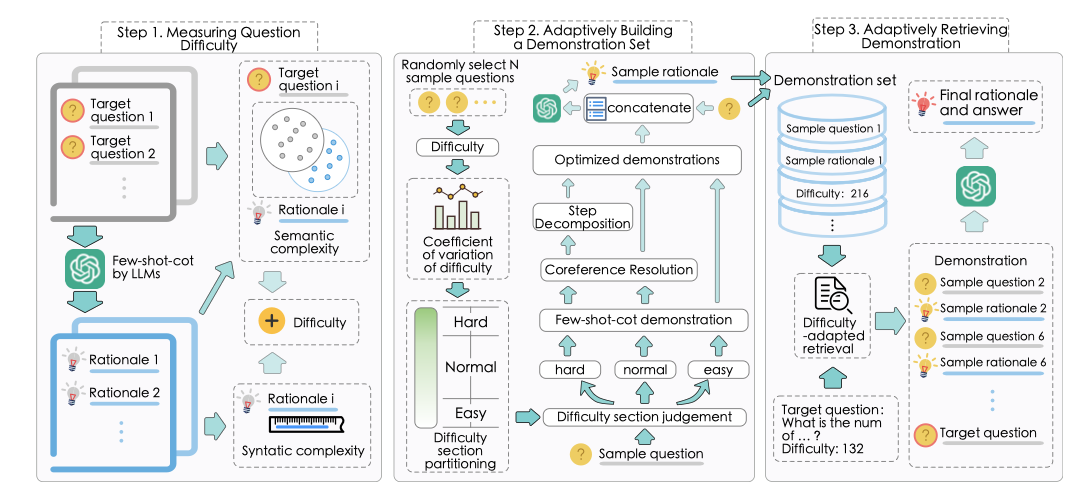
如图所示,第一步先让LLM为每个问题生成推理步骤,通过句法的复杂度和语义的复杂度来衡量每个问题的难度。
然后将问题划分为简单,普通,困难三个区间。最后,为不同难度的样本定制不同复杂度的推理实例。
最后,对于一个新的目标问题,先通过步骤一计算难度,然后从推理实例库中天选出和它难度相近的M个示例、最后,将M个难度匹配的问题注入LLM,形成Few
shot。
ARM: Adaptive Reasoning Model
文章要解决的问题
OverThinking
方法论
ARM的实现是一个两阶段的训练框架:
阶段一:SFT - 学会四种推理格式
目的:首先要教会模型不同的“招式”。
四种格式:
直接回答(Direct Answer):最快,没有推理过程。
短思维链(Short CoT):进行简短推理后给出答案。
代码(Code):用代码的结构化过程进行推理。
长思维链(Long CoT):最复杂、最耗费token,但能力最强,能进行自我反思和探索。
方法:通过在一个标注了四种格式答案的数据集(AQUA-Rat)上进行监督微调(SFT),让模型初步掌握这四种推理格式。
阶段二:RL - 学会如何选择格式
问题:经过SFT后,模型虽然会了四种招式,但并不知道什么时候该用哪一招,甚至会出现“格式错乱”的问题。
解决方案:Ada-GRPO:作者提出了Ada-GRPO(Adaptive GRPO),这是对标准GRPO算法的一个巧妙改进。
GRPO的问题(格式坍塌):标准的GRPO只看重准确率。由于“长思维链”通常准确率最高,GRPO会很快让模型只倾向于使用这一种格式,导致其他更高效的格式被“饿死”,这就是所谓的“格式坍塌”(Format Collapse)。
Ada-GRPO的改进:它引入了一个 “格式多样性奖励” 机制。在计算奖励时,它会给那些在当前采样批次中出现次数较少的格式一个临时的奖励加成。
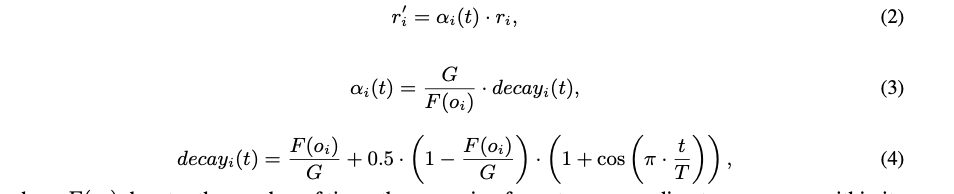
公式(3)
α_i(t):这个奖励缩放因子在训练初期会很大,它会“保护”那些虽然准确率不高但出现少的格式(如Short CoT),防止它们被淘汰。公式(4)
decay_i(t):随着训练的进行,这个加成会通过一个衰减因子逐渐减小,最终让模型的优化目标回归到准确率本身。
最终效果:通过这种“先鼓励多样性,后回归准确率”的机制,Ada-GRPO成功地训练ARM学会了根据任务难度自适应地选择最高效且能解决问题的推理格式。
AdaCtrl-Towards Adaptive and Controllable Reasoning via Difficulty-Aware Budgeting
文章要解决的问题
- OverThinking
- 能够让用户控制思考深度
方法论
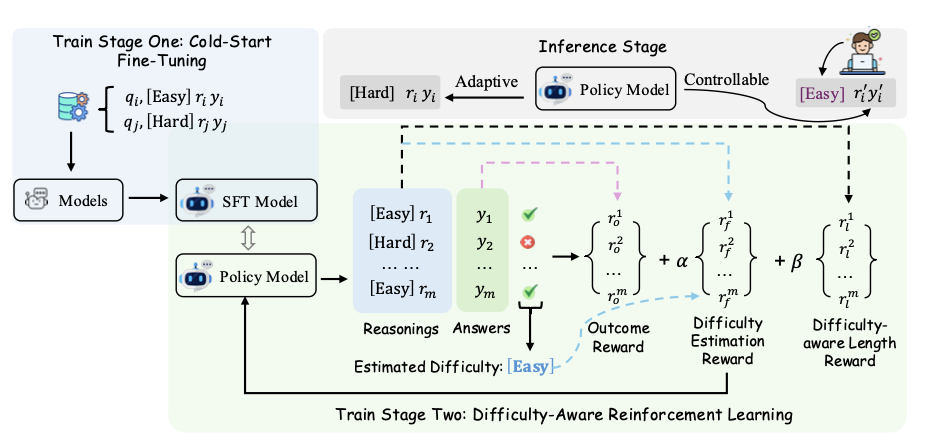
核心设计:长度触发标签 (Length-Trigger Tags)
为了实现可控性,作者设计了两个特殊的控制标签:
[Easy] 和
[Hard]。这两个标签就像是模型的“指令开关”,模型被训练成在生成回答的开头,先决定这个问题是“简单”还是“困难”,并输出相应的标签,然后根据这个标签来调整后续的思考深度
。同时,用户也可以在输入时直接提供这些标签来命令模型采用何种模式。
训练流程(见图):
阶段一:冷启动微调(Cold-Start Fine-Tuning)
目的:为模型打下基础,让它初步理解
[Easy]和[Hard]这两个标签的含义,并学会根据它们生成不同长度的回答 。方法:构建一个特殊的SFT数据集。从一个带有难度标注的数据集(DeepMATH)中,为简单问题生成简短回答并打上
[Easy]标签;为困难问题引入强大的教师模型(Deepseek R1)生成长篇回答,并打上[Hard]标签。然后用这个混合了两种难度和格式的数据集对模型进行SFT 。
阶段二:难度感知的强化学习(Difficulty-Aware RL)
目的:在SFT的基础上,通过RL进一步优化和校准模型的自适应能力 。
方法:设计一个复合的、包含三部分的奖励函数,并通过改进的GRPO算法(Ada-GRPO)进行训练 。
结果准确性奖励 (Outcome Reward):最基础的奖励,回答正确得正分,错误得负分 。
难度估计校准奖励 (Difficulty Estimation Reward):在RL的在线采样中,通过多次rollout的准确率来判断一个问题的真实难度。如果模型自己生成的难度标签(
[Easy]或[Hard])与这个真实难度相符,就给予奖励;不符则不给分。这能让模型对自己和问题的难度有更准确的“自知之明” 。难度感知的长度奖励 (Difficulty-aware Length Reward):这是一个非对称的长度奖励。只有当模型为问题打上
[Easy]标签时,才会激活长度奖励,此时回答越短,奖励越高。如果模型判断问题是[Hard],则完全没有长度惩罚,允许它进行充分思考 。
通过这个两阶段框架,AdaCtrl最终学会了在没有用户指令时(自适应模式),能先自我评估难度再决定思考深度;在有用户指令时(指令引导模式),能精确地遵循指令进行长篇或简短的思考。
THINK SMARTER NOT HARDER: ADAPTIVE REASONING WITH INFERENCE AWARE OPTIMIZATION
文章要解决的问题
OverThinking
方法论
理论推导与算法设计:
问题形式化:
首先,将所有可能的回答划分成不同的
组(group),例如
G_0代表“标准长度的CoT回答”,G_+代表“扩展长度的回答” 。然后,设定一个
约束条件:要求模型生成“扩展回答”
y ∈ G_+的平均概率不能超过一个预设的预算上限q_+。最终的优化目标是:在满足这个预算约束的前提下,
最大化任务的奖励(准确率) 。
从优化问题到SFT更新(核心推导):
直接在LLM的参数空间求解这个带约束的优化问题非常困难 。
作者采取了一种“两步走”的思路:先在一个非参数化的、更简单的空间里求解出理论上的最优回答分布
π*,然后再将这个最优解“投影”回LLM的参数空间进行学习 。经过一系列数学推导(使用stop-gradient技巧来简化计算 ),作者惊奇地发现,这个复杂的优化过程最终可以简化为一个非常直观且易于实现的算法:带权重的迭代式监督微调(weighted iterative SFT) 。
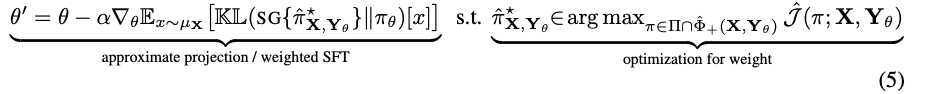
不过,总而言之,它的想法是容易学习的,通过约束生成的长思考的比率,限制模型的输出。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

