


今天应该就一篇
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
想要解决的问题
和前一篇THINKPRUNE一样,也是为了解决CoT过长,过度思考的问题。看得出来,S1这篇文章做的事情太trival了,很多人都不是很喜欢这种强硬的改法。
方法论
最初有的:
然后作者通过
得到了新的prompt,从而构建了一个新的数据集
然后他们用GRPO算法,通过下面的这个reward训练大模型。
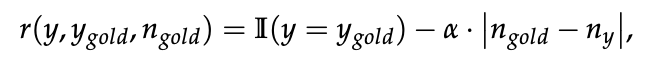
其中,
然后作者可能觉得工作量不够吧,又多做了一个方法。作者将其称之为
作者用了一个新的rule-based reward
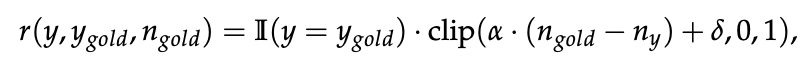
根据
实验
baseline是和Ds-1.5B,DeepScaleR-1.5B,DeepScaleR-1.5B-4K和S1进行比较。
LCPO的基模型是DeepScaleR-1.5B,也就是说和DSR-1.5B的比较才是比较真实的体现
作者特别在实验设置中分享了超参数,嗯,实验应该是可信的。
实验结果如下:
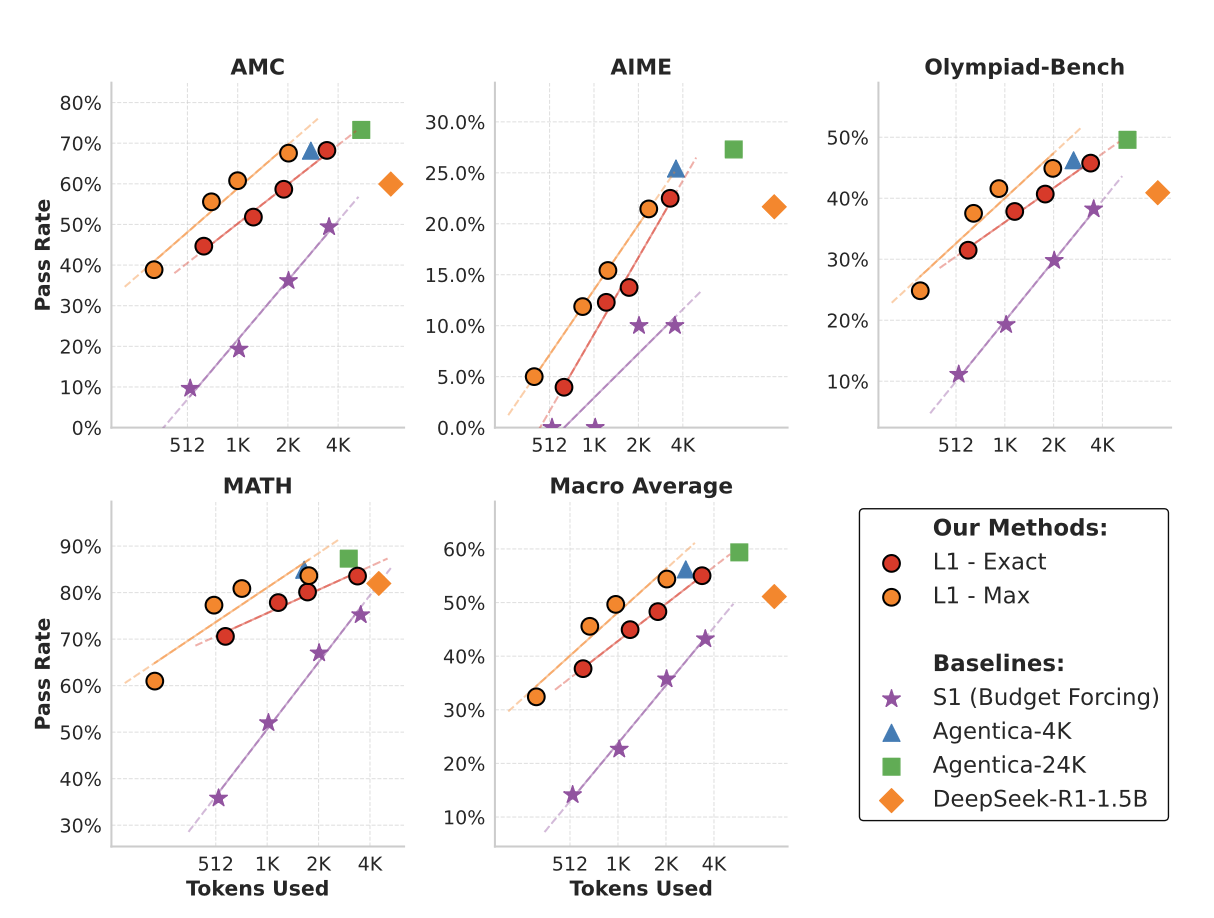
吐槽一下,这实验做的也太穷了= =。这后面这俩模型基本就跑了一遍…
基本上可以确定的是,L1-Max的性能肯定比L1-Exact的效果要好一点。这和我的insight一致,你强制推理长度肯定会出问题的,你这简单问题都要用那么长的CoT,肯定不对。
不过这Performance只能说明他的效果比S1好,然而S1被爆是肯定的,但是他自己的性能其实也没干过Agentica-4K,基本也就比24K的好一点…
而且,这里的对比有一些问题,他说,L1的模型在训练的时候会用到4K,但是评估的时候用的是8K的上下文。这不统一长度评估都没控制变量啊。虽然用的方法差不多,都是GRPO,但是这篇显然没有前面那篇THINKPRUNE的效果好。
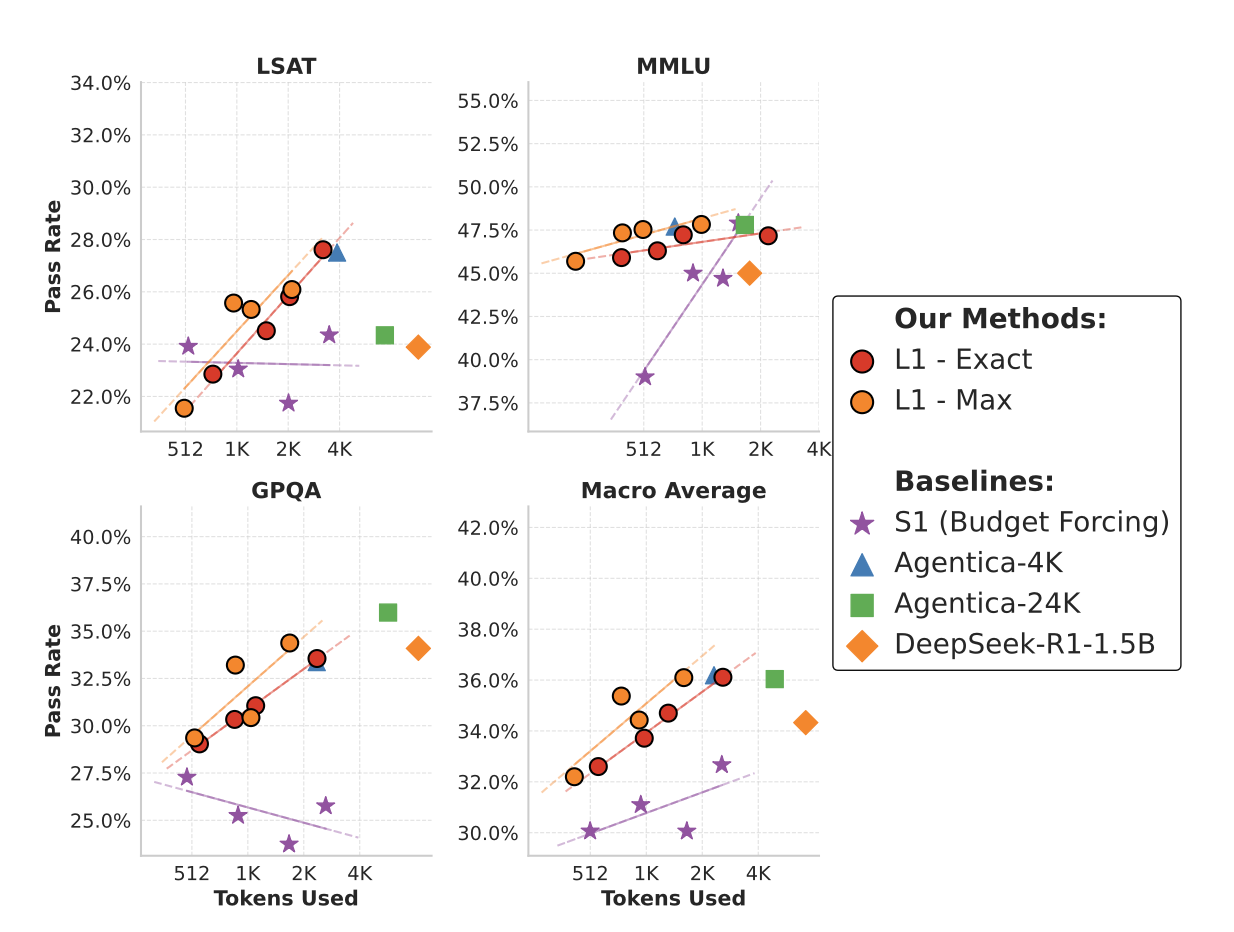
第二个实验,在面对OOD的时候,这个模型的优势在于,能够维持一定的推理能力。这里就体现出RL的牛逼了,他能够探索出人类想象不到的action。S1一样被爆了。
补充实验部分的insight
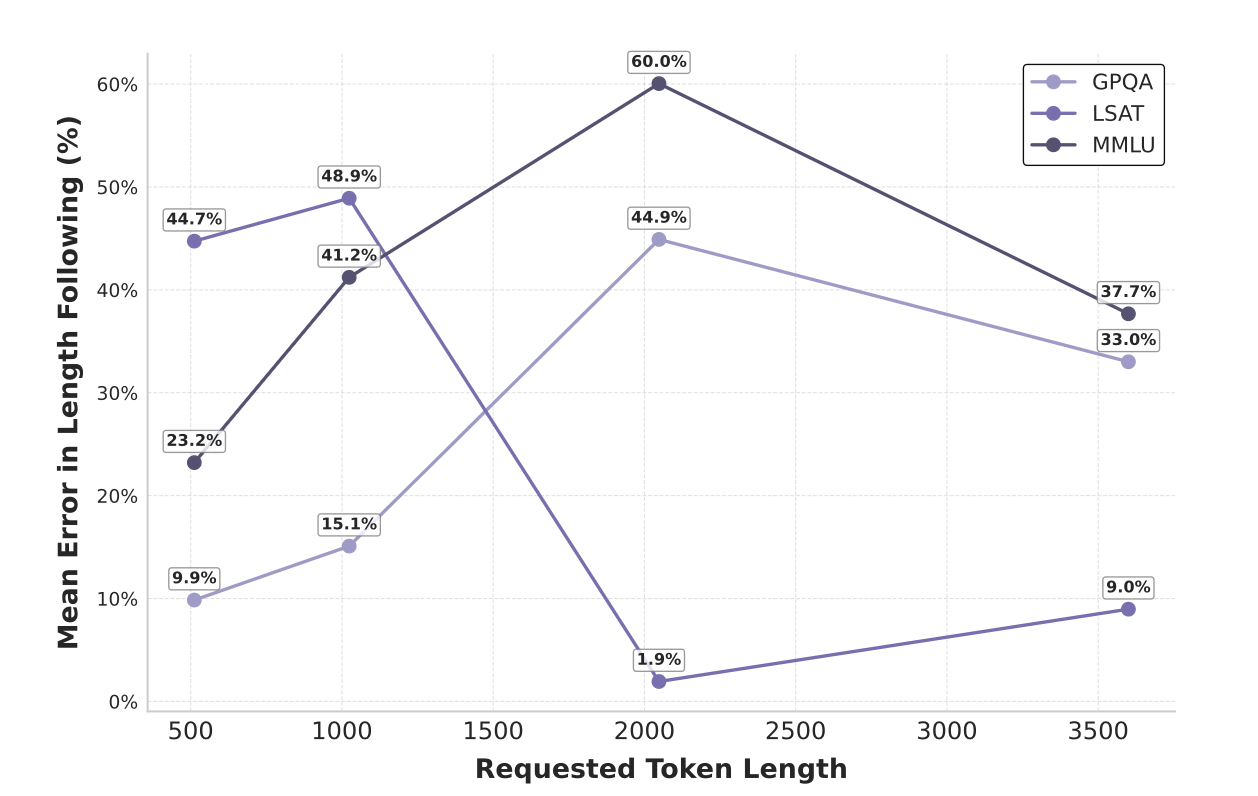
作者在这里补充了一个对于OOD的数据集,模型的表现。即不同请求长度下,模型生成长度和误差分布的相关性。
很有意思的是,对于OOD的数据集,并不总是长的推理带来低错误率,反而比较少的token也可以带来不错的正确率。我的理解是,不同的问题并不一定需要限制其在固定的推理长度上。推理正确的重要性应该远远大于限制的重要性。如何在这之中取得平衡是一个比较难的问题。
因此,future
work可以是,如何构造训练范式,使得模型能够知道,什么样的任务需要长思考,什么样的任务需要短思考。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

