


今日第一篇:When To Solve, When To Verify:Compute-Optimal Problem Solving and Generative Verification for LLM Reasoning
主要解决的问题
majority voting 和GenRM的方法需要在统一compute
allocation的前提下进行比较。单一的进行准确性的比较是片面的。
直觉上来讲,majority
voting在计算量小的情况下能够达到比较理想的结果,而对于比较多而长的思维链,我们需要用GenRM来减少计算量。
新名词:GenRM介绍
GenRM采用了一种截然不同的、全新的范式:
工作方式与目标:GenRM将“奖励建模”这个任务重新定义为一个标准的生成任务(Generative Task)或分类任务。它不输出一个抽象的分数,而是直接生成代表偏好的“答案指示符”(例如,生成文本”A”或”B”)。
模型架构:它不需要额外的模型架构(如线性预测头)。它就是语言模型本身,利用其固有的续写能力来完成判断。
输出:
基础GenRM:直接生成代表偏好的指示符(A或B)。
CoT-GenRM:在给出最终偏好判断之前,会先生成一段 “思维链”(Chain-of-Thought)推理,用自然语言解释为什么它认为某个回答更好。
本质:这是一种生成式(Generative)的方法。它不仅做出判断,还能通过生成的文本来解释其判断的理由,尤其是CoT-GenRM变体。
核心不同点总结
| 特性 | GenRM (生成式奖励模型) | Bradley-Terry RM (结果奖励模型 ORM) | ||
|---|---|---|---|---|
| 工作方式 | 生成式:通过生成文本(答案指示符或推理过程)来表达偏好。 | 判别式:学习一个函数来为每个回答打分。 | ||
| 模型架构 | 无需额外架构,就是LLM本身。 | 在LLM之上需要一个额外的 | 线性预测头来输出分数。 | |
| 输出内容 | 文本(如”A”)或”推理过程 + 文本”。 | 一个 | 标量奖励分数。 | |
| 可解释性 | 高,尤其是CoT-GenRM,它会生成自然语言的推理过程来解释其判断。 | 低,只给出一个分数,不解释原因。 | ||
| 核心优势 (据论文) |
在跨领域(Out-of-Distribution)任务上泛化能力更强,更稳健。 | 在领域内(In-Distribution)任务上准确且有效。 |
总而言之,最根本的区别在于:传统的ORM像一个只打分的裁判,而GenRM则像一个会写详细“判决书”的法官。GenRM通过利用LLM自身的生成和推理能力,将奖励建模从一个简单的“打分问题”转变为一个更透明、更具可解释性的“推理和论证问题”。
方法论
作者用自监督的方法微调了一个模型,用于专门来生成verification。主要是通过将原模型生成的所有的solution和真正的solution灌给一个很强的模型,用于生成其coT数据和最后对于推理正确的判断。就有了一个微调的数据集。
然后我们把数据集用来微调一个模型,那么就有了可以verification的模型。
实验部分
motivation实验
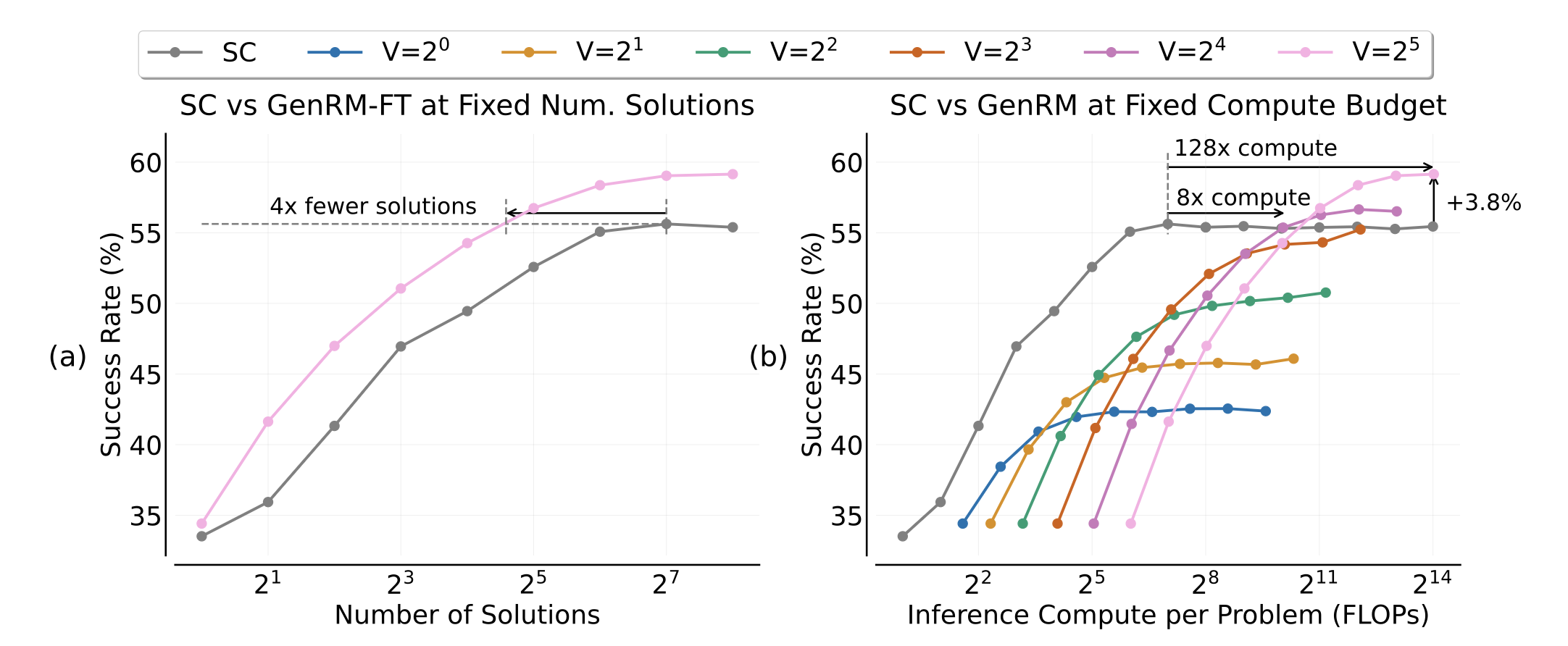
左图中,粉线是GenRM,灰线是Majority
voting,可以发现,在限定解的数量的情况下,明显GenRM能在更少的解的情况下达到更高的accuracy。
右图中,灰线依旧是Majority
voting。不同颜色的线代表GenRM为每一个解决方案生成的验证次数。很容易可以发现,在计算量固定的情况下,计算量少的时候,Majority的结果远远超过基本所有的GenRM,而GenRM在推理资源消耗大的情况下才能达到更好的准确率。
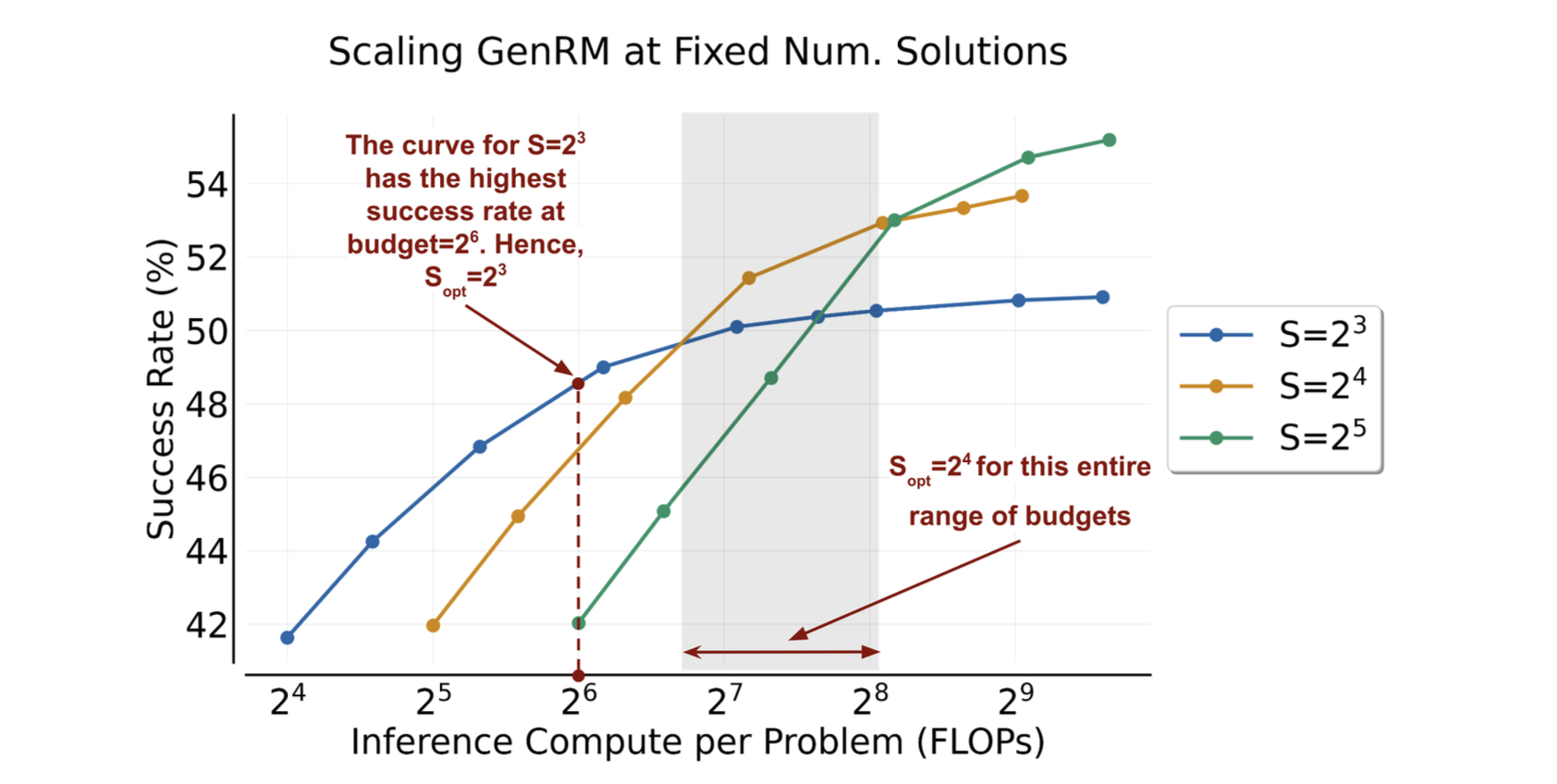
该实验旨在说明如何为GenRM选择对应的生成的solution数量。目的是让在给定计算资源的情况下平衡Solution的数量和Verification的数量。
第二篇:THINKPRUNE- Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
主要解决的问题
现在的LLM存在OverThinking的现象,对于这种问题,一般可以在训练的时候对reward model进行长度惩罚来解决。但是没有人提出对已经预训练好的模型进行防止OverThinking的办法,而且,现有的直接截断的方法过于粗暴,会导致性能的大幅下降。
方法论
本文提出了一种名为THINKPRUNE的新方法,旨在通过RL再训练模型,引入一个严格的token长度上限,任何超出上限的思考和答案都会被裁断,通过GRPO算法使得rule-based的方法中最终得到的奖励为0。迫使模型学会短式的思考。
为了最大幅度的保持模型的性能,本文追加了一种迭代式裁剪的办法,即分多个阶段,逐步收紧长度限制进行训练,让模型更平滑的适应这个过程,避免推理能力的下降。
reward model
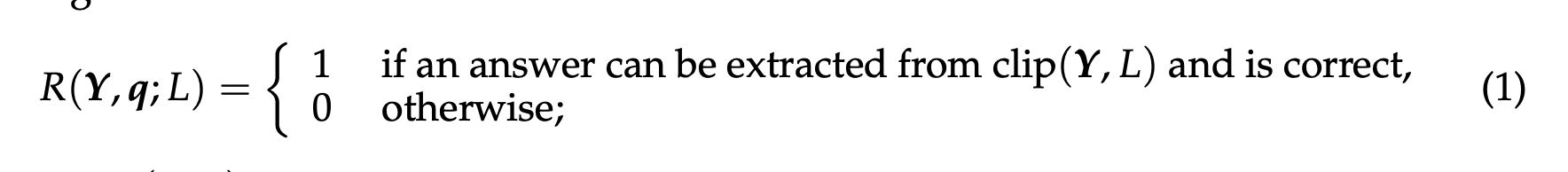
实验
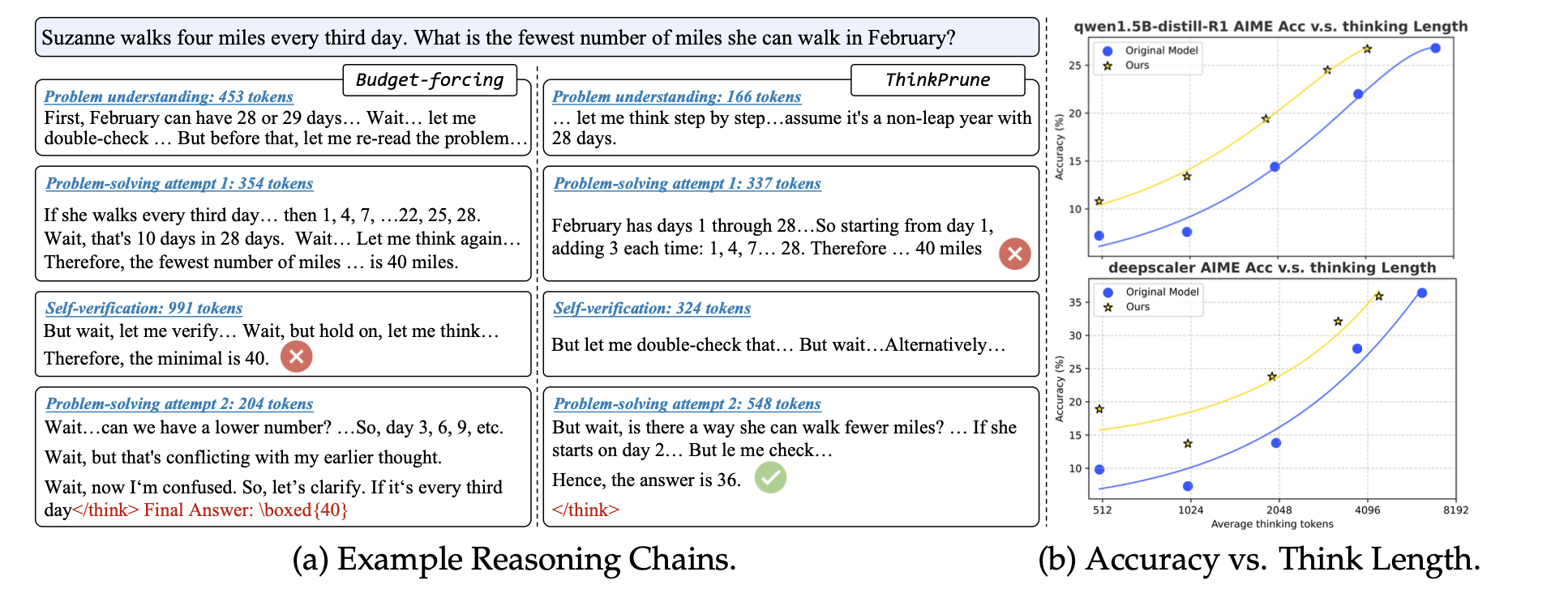
从右侧的图b来看,他们能够做到在相同平均输出长度下,模型的准确率的大幅提高。
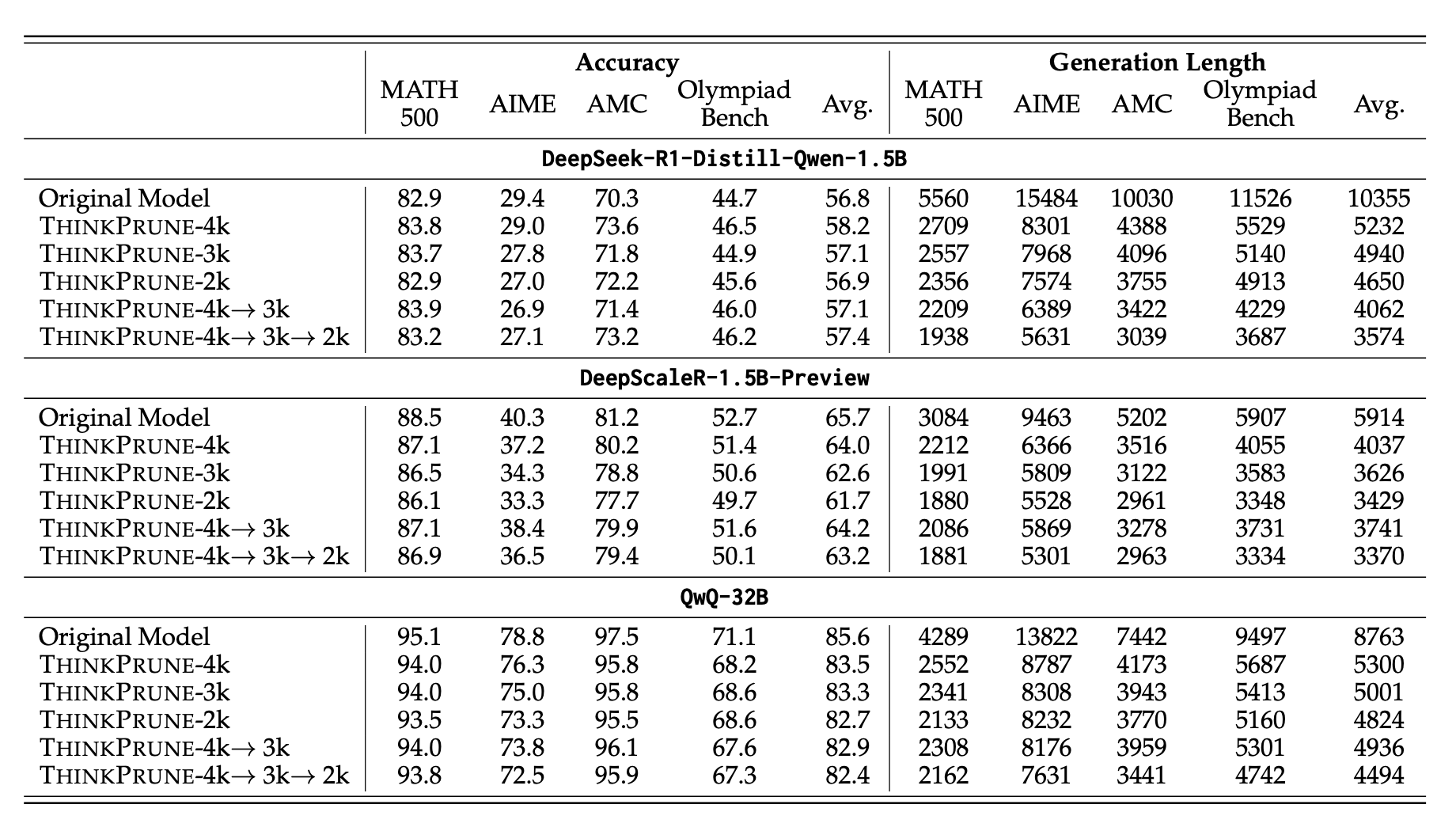
从这张表来看,他们的模型能够在推理能力基本不变的情况下,使得输出的长度显著的降低。
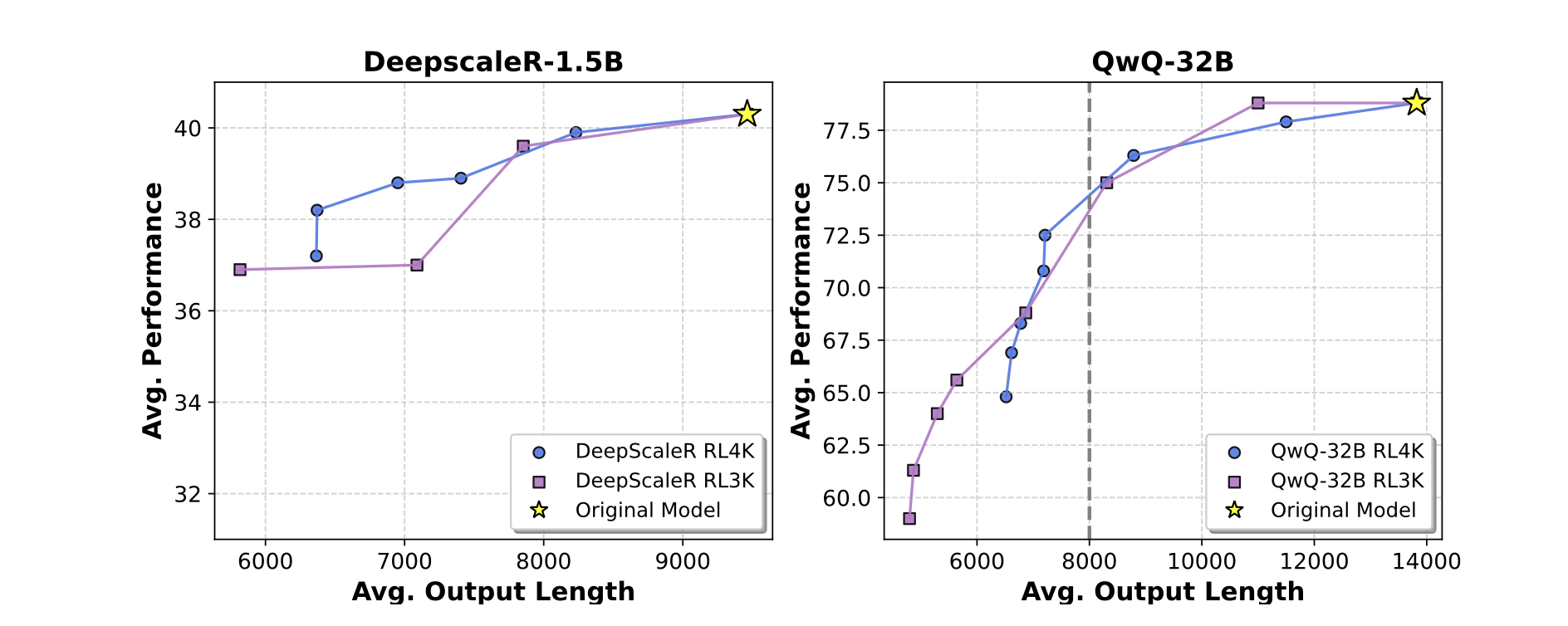
这张图展示了该算法权衡推理能力和推理长度的能力。横坐标是平均的输出长度,纵坐标可以理解为是平均的正确率。可以看到,在早期的output
Length的改变没那么大的时候,模型的推理能力下降的非常平缓,但是一旦平均输出长度下降过大,那么推理能力立刻雪崩。
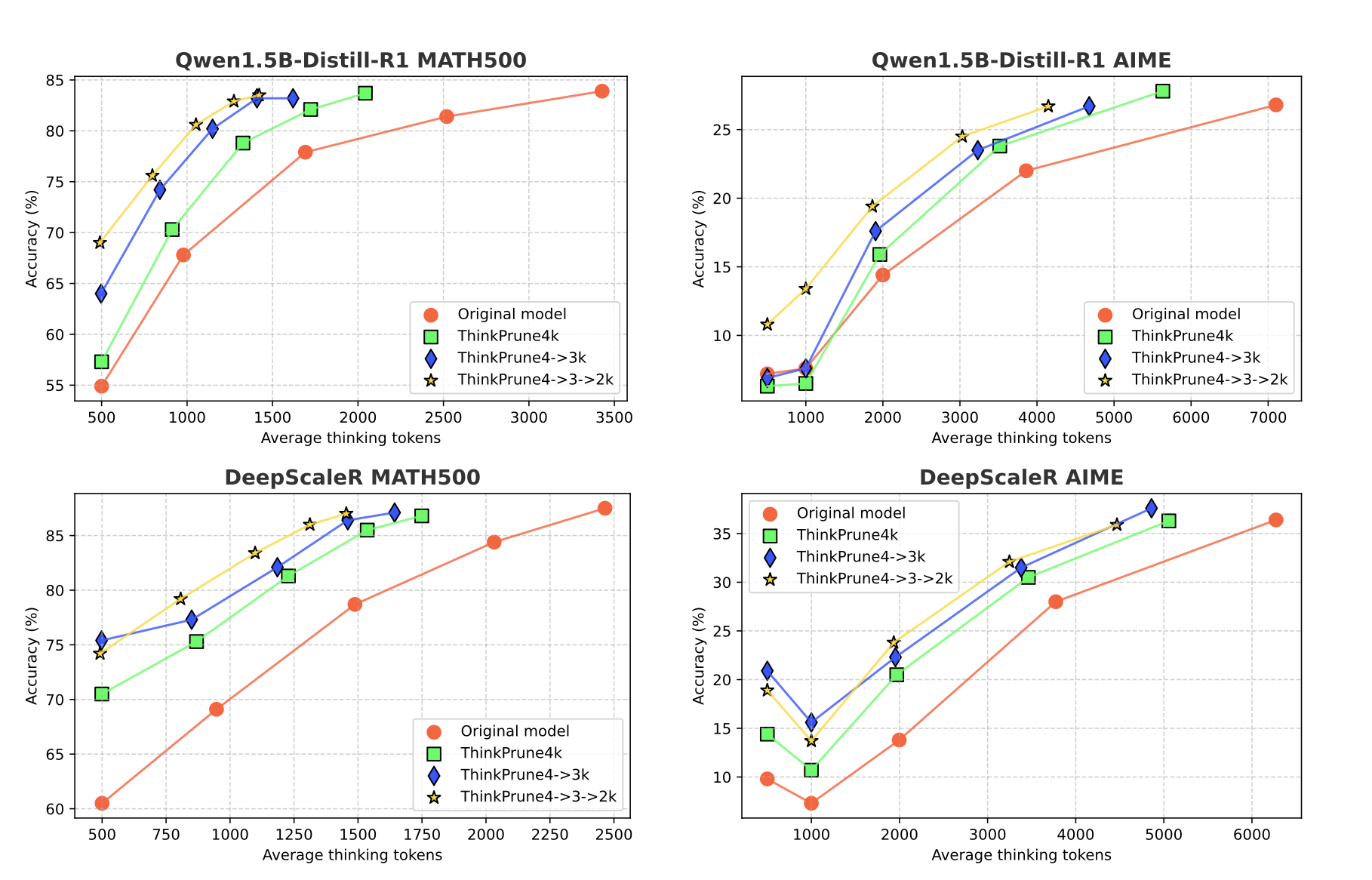
最后,作者在多个模型上都试了一下这个算法,基本上可以肯定,迭代式的算法效果会更优。其实这个图横过来看会更有道理一点,在同样的准确率下,他们的平均输出长度显然要更低一些。
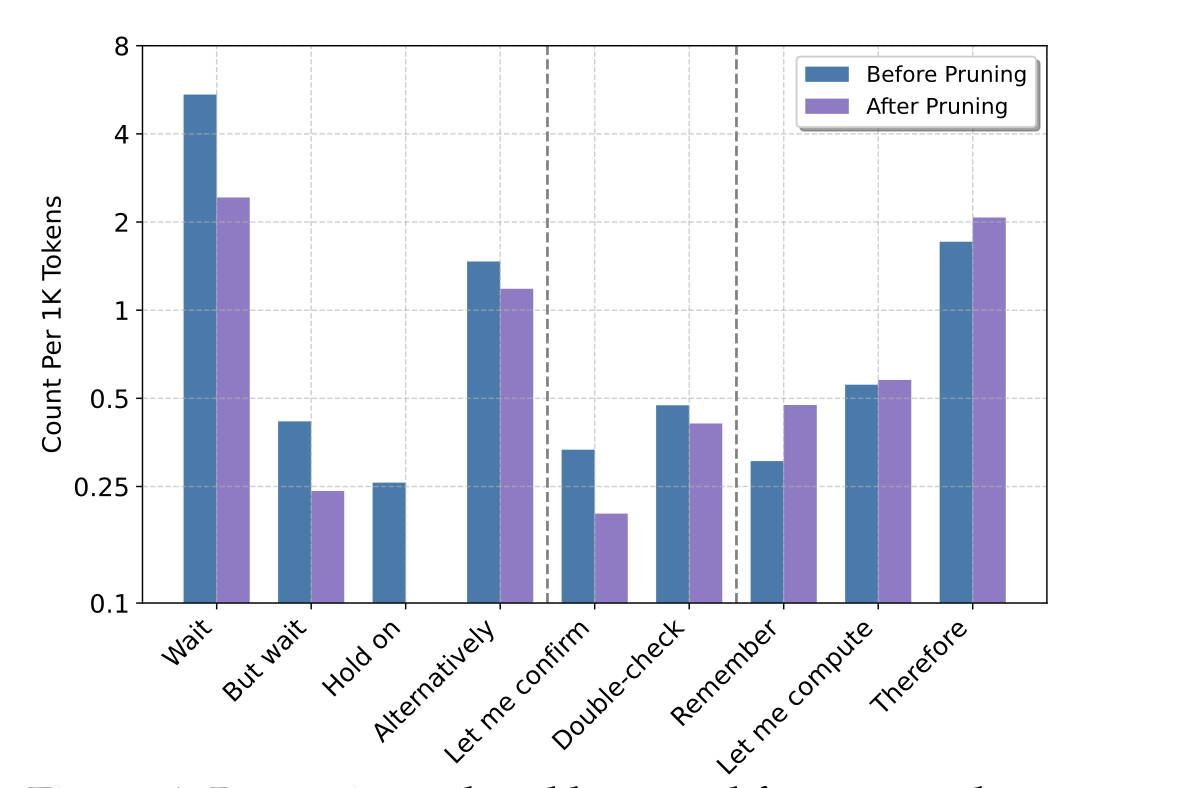
最后,作者总结了一下在应用这个方法前后,模型输出推理关键词的频率。
可以看出,基本上Wait,But
wait这种想要尝试另一种方法的推理关键词的分布显著的减少,而Therefore,
Remember这种推理性质更强一些的关键词则显著的增强。
总结
这篇文章真的还是挺有意思的,RL被用到剪枝长度的过程确实取得了非常不错的效果,并且作者也开源了代码,复现上应该基本不会有问题。这也引发了我的一个小小思考,推理关键词在推理中的作用是什么样的存在,如果能够显著的提高部分关键词的概率,是否可以增强模型的推理能力呢?另外,如何让模型知道哪些思考是必要的,哪些思考是不必要的,是否可以结合PRM进行新的探索呢?
今天的事情比较多,就读了两篇,明天多读吧~
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

