


DPO算法的基本推导过程
回顾RLHF
RLHF主要做了两个事情
1、构建RM,用于ppo的训练
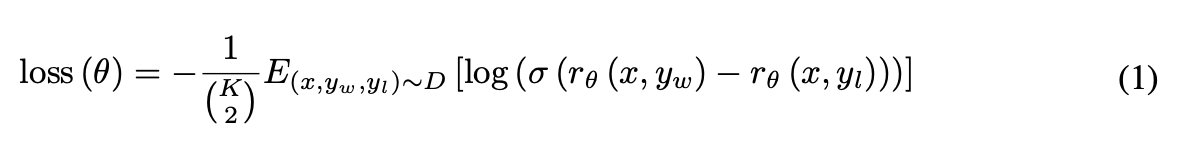
2、构建优化对象
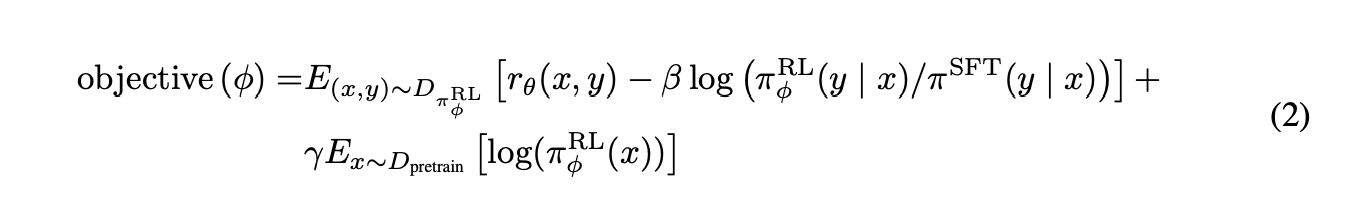
DPO的思路
我们知道,构建RM的思路是最大化
即:用模型的分布,表出对于模型对这个答案的偏好程度即可。我们只要让模型对这两个的偏好能够区分开就行。
那么怎么利用模型的分布表出偏好程度呢?这里的思路有很多,但是DPO是直接从RLHF的(2)式子去求解的,在最大化这个object的前提下,求解出
具体求解过程如下:
$$
$$
其中,
通过这么一番操作,我们最后优化的结果是
根据吉布斯不等式,我们容易知道,前面这个KL散度是恒大于等于0的,
由此可以解出我们的
$$
$$
于是我们将我们求出的reward model代入一开始的loss函数可得
$$
$$
最终 DPO:
$$
L_{DPO}({}; {}) = -_{(x, y_w, y_l) D}
$$
DPO的后世变体
早期思路探索
SLiC-hf (Sequence Likelihood Calibration with human feedback)
核心理念:作为DPO的先驱,它旨在通过一个简单的对比学习损失函数,直接“校准”模型的输出概率,使其符合人类的偏好顺序。
工作流:
准备一个基础模型和成对的偏好数据(提示、好回答 y+、坏回答 y−)。
模型计算出生成 y+ 和 y− 的概率。
通过一个“排名校准损失函数”进行优化,该函数旨在确保 y+ 的概率比 y− 的概率高出一个指定的边际(margin)。
使用该损失更新模型参数。
关键区别:这是最基础的直接偏好校准方法,可以看作是DPO思想的一个更简单、更直接的实现。
2. DPO (Direct Preference Optimization)
核心理念:作为基准方法,它通过一个巧妙的数学推导,绕过了传统RLHF中复杂的奖励模型训练和强化学习采样过程,直接从偏好对中优化语言模型。
工作流:
从一个基础模型(通常经过SFT)和偏好数据集开始。
它在理论上将奖励函数重新定义为“偏好回答”与“不偏好回答”的策略概率比。
基于此,它推导出一个封闭形式(closed-form)的最优策略解,从而将复杂的强化学习问题转化为一个简单的、类似二元分类的损失函数进行优化。
关键区别:这是所有直接偏好优化方法的基石。它的核心创新在于证明了可以跳过奖励模型,通过一个简单的损失函数直接达到类似RLHF的对齐效果。
DPO的改进与变体
3. β-DPO
核心理念:解决标准DPO中正则化强度
β是静态的、一成不变的问题,通过动态调整β来适应不同批次数据的学习难度。工作流:
在每个训练批次开始前,评估该批次数据的“平均奖励差距”或“信息含量”。
如果数据对的差距小(难学、信息量大),则动态调低
β值(放松约束,鼓励模型学习)。如果数据对的差距大(好学、信息量小),则动态调高
β值(加强约束,防止过拟合)。
关键区别:将
β从一个固定的超参数,变成了随数据质量动态变化的变量,使训练更智能、更稳健。
4. sDPO (Stepped DPO)
核心理念:采用“课程学习”的思想,将偏好数据集分成多份,进行增量式、分步骤的训练,逐步提升对齐标准。
工作流:
将偏好数据集D分为D1, D2, …, Dn。
第1步:用D1对基础SFT模型进行DPO训练,得到模型M1。
第2步:将M1作为新的、更强的“参考模型”,再用D2对其进行DPO训练,得到M2。
以此类推,逐步完成所有数据的训练。
关键区别:将一次性的训练过程变为阶梯式的、逐步求精的过程。这有助于稳定训练,并让模型从易到难地学习。
5. RSO (Statistical Rejection Sampling Optimization)
核心理念:在优化前,先通过一个辅助的奖励模型进行“拒绝采样”,主动提纯和构造出更高质量的训练数据。
工作流:
先用偏好数据训练一个简单的“奖励排序模型”。
让基础模型生成大量候选回答,并用步骤1的奖励模型给它们打分。
根据分数进行统计拒绝采样,保留高质量的回答,组成一个经过“提纯”的、新的偏好数据集。
最后用这个高质量数据集对模型进行优化。
关键区别:核心在于数据提纯。它不是被动地使用现有数据,而是主动地去创造一个更好的数据集,以期达到更好的训练效果。
6. GPO (Generalized Preference Optimization)
核心理念:它本身不是一个具体算法,而是一个通用的数学理论框架,旨在统一DPO、SLiC等多种偏好优化方法。
工作流(理论层面):
GPO框架的核心是选择一个“凸函数”。
不同的凸函数选择,会使GPO框架具体化为不同的偏好优化算法(如选择逻辑函数得到DPO,选择铰链函数得到SLiC)。
关键区别:这是一个元方法或理论模型,其价值在于为理解和分析各种直接偏好优化算法提供了统一的视角。
7. DRO (Direct Reward Optimization)
核心理念:改变了数据格式,使用更易于收集的“单回答+直接评分”数据(例如,给一个回答打1-5星),而不是成对的比较数据。
工作流:
使用(提示,回答,分数)格式的数据。
优化一个二次目标函数,旨在最小化“给定的分数”与“模型计算的期望奖励”之间的差距。
同样使用KL散度进行正则化约束。
关键区别:能够利用非成对的、带绝对分数的单轨迹数据,这可能大大降低数据标注的成本。
面向特定挑战的DPO变体
8. D²O (Distributional Dispreference Optimization)
核心理念:一个专注于安全性的变体,它在分布层面进行优化,以更有效地“反学习”(unlearn)有害内容,避免模型在规避单个坏样本时产生新的问题。
工作流:将模型的输出分布与一个由人类标注的“不偏好样本”的整体分布进行对比,并优化模型以拉大这两个分布之间的差距。
关键区别:从“实例级别”的规避升级到“分布级别”的规避,使安全对齐更全面、更鲁棒。
9. NPO (Negative Preference Optimization)
核心理念:一个更极致的安全对齐方法,它只使用负面样本(不想要的回答)来进行“反学习”。
工作流:其损失函数只专注于降低模型在不期望数据上生成内容的置信度,完全不需要正面样本。
关键区别:是专门为“反学习”或“内容擦除”任务设计的,不需要任何“好回答”数据。
10. DPOP (DPO-Positive)
核心理念:修复DPO在处理好坏回答非常相似(编辑距离近)时,可能意外降低“好回答”本身概率的特定缺陷。
工作流:在标准DPO的损失函数上,增加一个额外的修正惩罚项。这个惩罚项确保“好回答”的概率不会因优化过程而下降到低于参考模型的水平。
关键区别:是一个针对性修复,确保模型在学习细微差别时“不会为了打倒坏的而伤害好的”。
11. TDPO (Token-level DPO)
核心理念:将DPO的优化粒度从句子级别下沉到更精细的词元(token)级别。
工作流:将文本生成视为一个马尔可夫决策过程,在每个词元上应用类似于DPO的偏好优化,并引入词元级别的KL散度约束。
关键区别:实现了更细粒度的控制,可能在处理内容多样性和分歧时更有效。
基于博弈论和理论创新的DPO变体
12. DNO, SPPO, SPO (基于博弈论的变体)
核心理念:这类方法(DNO, SPPO, SPO)都从博弈论或社会选择理论中汲取灵感,将对齐过程建模为玩家之间的“博弈”。
工作流(共通思想):通过“自我博弈”(self-play)的机制,让模型生成相互竞争的回答,并根据“胜率”等博弈概念来定义奖励或优化目标,从而找到一个稳定的“纳什均衡”策略。
关键区别:引入了博弈论作为新的理论基础,为解决复杂的偏好聚合问题提供了更稳健的框架。
13. ΨΡΟ (IPO), KTO, CPO (其他理论创新的变体)
ΨΡΟ / IPO: 旨在通过优化偏好概率的非线性函数来避免过拟合,尤其是在处理确定性很强(即答案几乎是唯一)的偏好数据时。
KTO: 灵感源自前景理论,它无需成对偏好数据,而是将每个回答单独标记为“可取”或“不可取”,进一步简化了数据需求。
CPO: 旨在提升DPO的计算和内存效率,它通过修改损失函数,使得在训练过程中可以移除参考模型,从而能用更少的资源微调更大的模型。
关键区别:这些方法分别从避免过拟合、简化数据、提升效率等不同理论角度对DPO进行了深度优化和改进。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

