


核心任务
- 为端用户提供大量应用服务
- 协议可能数量非常多且复杂
- 每个协议都为一个应用专门化的定制,无通用协议
服务器-客户端模式
服务器:
- 提供永久的IP地址,方便客户建立连接
- 永远在线
- 服务器可拓展
客户端:
- 建立连接后直接和服务器通信
- 动态IP
- 间歇性连接
- 不直接和其他客户端通信
P2P模式
- 对等节点直接建立连接
- 节点使用动态的IP
DNS域名解析系统
- 主要功能:将域名映射为IP地址
- 层次命名空间:
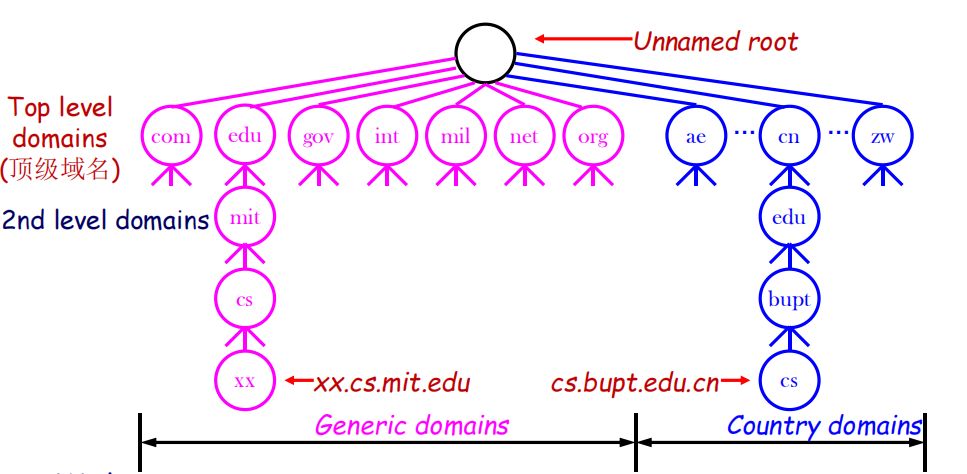 可以优化查询流程,先从顶层域名一步步往下递归查询,方便管理域名和对应的管理服务商
可以优化查询流程,先从顶层域名一步步往下递归查询,方便管理域名和对应的管理服务商
- 分级域名服务器:
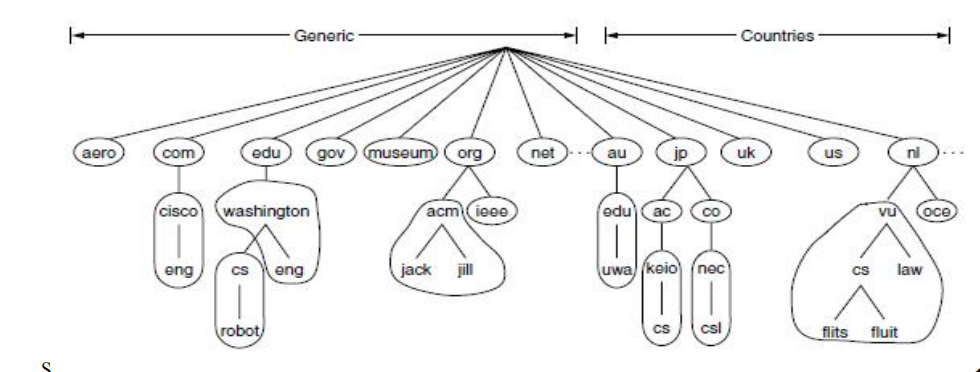 如图所示,按照分级管理的方式,一个域对应一个管理机构,对应的管理机构需要管理它的分支底下的部分
如图所示,按照分级管理的方式,一个域对应一个管理机构,对应的管理机构需要管理它的分支底下的部分
| 服务器名称 | 根域名服务器 (Root) | TLD域名服务器 (TLD) | 权威域名服务器 (Authoritative) |
|---|---|---|---|
| 职责 | 指明去哪个TLD服务器查询 | 指明去哪个权威服务器查询 | 给出最终的IP地址答案 |
| 知识范围 | 知道所有TLD服务器的地址 | 知道其管理的TLD下所有域名的权威服务器地址 | 知道其管理的域名下所有主机的具体记录 |
| 层级 | 最高层 (Top) | 中间层 (Middle) | 最底层/最终目的地 (Final) |
| 查询角色 | 引导员 (Director) | 指路人 (Navigator) | 最终答案提供者 (Answer Provider) |
- RR(Resource Record):DNS会将域名映射到对应的资源记录上,RR可以看作是一个记录,每一个RR含有如下信息:
| 字段名称 | 简称/缩写 | 说明 | 常见值/示例 |
|---|---|---|---|
| Domain_name | 本条记录适用的域名。 指定这条资源记录是归属哪个(子)域名的。 | www.example.com example.com (主域名)
mail.example.com |
|
| Time_to_live | TTL | 存活时间(单位:秒)。 指示其他DNS服务器或解析器在查询到这条记录后,可以缓存此信息多长时间。到期后必须重新查询权威服务器。TTL越长,变更生效越慢,但对权威服务器的查询压力越小。TTL越短,变更生效越快,但查询压力增大。 | 3600 (1小时) 86400 (1天) |
| Class | 协议族类别。 指定记录适用于哪类网络协议。 | IN:最常用的类别,代表Internet信息。 |
|
| Type | 记录类型。
最关键的字段之一,决定了这条记录存储的是什么类型的信息以及Value字段的格式和含义。 |
A - IPv4地址 AAAA - IPv6地址
NS - 名称服务器 CNAME - 别名
MX - 邮件交换 TXT - 文本信息
PTR - 指针(反查) |
|
| Value | Rdata | 记录值。
存储与 Type 相对应的具体数据。其内容完全取决于 Type。 |
192.0.2.1 (A记录)
ns1.example.com (NS记录)
mail.example.com (CNAME记录)
10 mailserver.example.com (MX记录) |
- 运行过程:
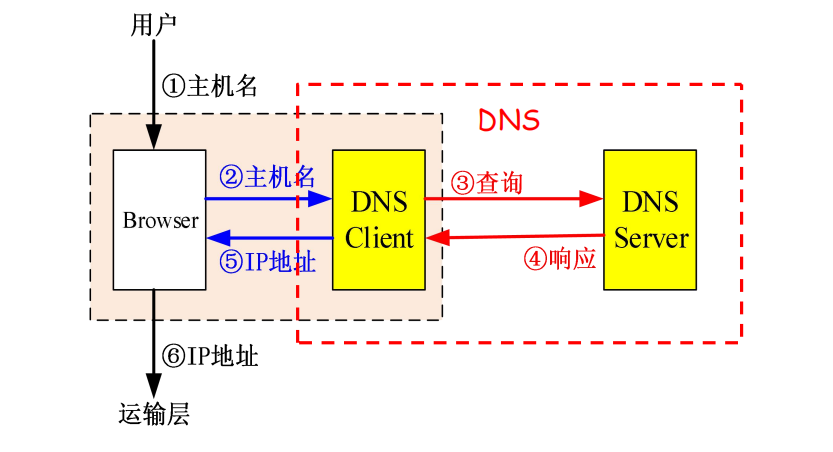
- DNS客户端:DNS服务请求和DNS服务器之间隔了一个DNS客户端,用于本地进行缓存。同时也防止直接对DNS访问进行DDOS攻击。当本地缓存查询不到的时候,才会询问DNS服务器。
- DNS服务端:主要分为两类,权威域名服务器和本地域名服务器
- 权威域名服务器:权威服务器包含了它所管辖的“域”中所有主机的官方记录。一条“权威记录”意味着它直接来自负责管理这个域的机构。因此,这个答案被认为是绝对正确、最终的。它不是一个缓存的、可能过期的副本,而是第一手资料
- 本地域名服务器:它不是任何特定域的权威服务器。它通常由你的互联网服务提供商(ISP)、你的公司或学校网络提供。你在电脑或路由器里设置的“DNS服务器”(如
8.8.8.8或114.114.114.114)就是本地域名服务器。他可以替你完成整个查询的功能,只返回对应的IP地址给你。
- 协同工作(域名解析)过程:
- 每个服务器都知道根服务器,每个进行DNS查询的服务器都会有一个”启动列表”,其中包含全球13个根域名服务器集群的IP地址,这是查询的起点
- 根服务器中会存储TLD的服务器的地址(比如.com服务器)
- 每个TLD服务器都知道层级中下一层服务器的地址(比如bupt.com)
- 最终由权威域名服务器给出结果
- 每个服务器都知道根服务器,每个进行DNS查询的服务器都会有一个”启动列表”,其中包含全球13个根域名服务器集群的IP地址,这是查询的起点
- 域名解析方式:
- 递归查询:如果被查询的服务器并没有储存结果,它也需要执行查询。查询服务器执行另一个递归查询,直到得到所需的答案返回。它不返回部分答案。
- 迭代查询:如果查询的服务器没有该信息,它可能会用另一台服务器的地址作为响应(部分答案);本地名称服务器(代表解析器)随后会向该服务器进行查询(它可能会用另一台服务器的地址作为响应,如此循环)
- 递归查询:如果被查询的服务器并没有储存结果,它也需要执行查询。查询服务器执行另一个递归查询,直到得到所需的答案返回。它不返回部分答案。
- 权威域名服务器:权威服务器包含了它所管辖的“域”中所有主机的官方记录。一条“权威记录”意味着它直接来自负责管理这个域的机构。因此,这个答案被认为是绝对正确、最终的。它不是一个缓存的、可能过期的副本,而是第一手资料
- Cache
- Cache中会缓存所有的查询信息和中间结果(中间服务器的信息),为了快速响应下一次查询。
- 缓存中的内容需要有TTL,超过这个时间之后,缓存作废。这样是为了保证权威性
- 使用缓存可以极大的减少查询步骤,提高性能
- Cache中会缓存所有的查询信息和中间结果(中间服务器的信息),为了快速响应下一次查询。
Email-电子邮件
核心目的
提供一种方式,使一个人可以异步地向另一个人发送电子消息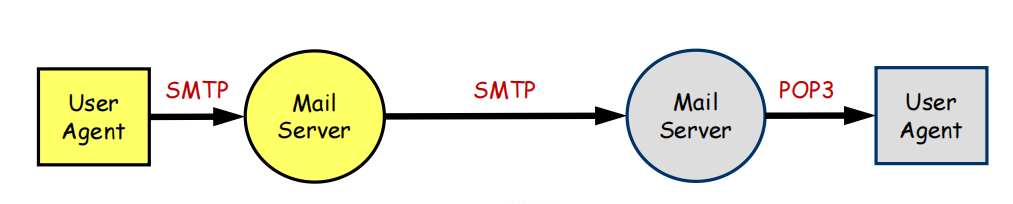
如图所示,每个用户需要有他们自己的邮局服务器,邮局服务器24h工作并监听对应的服务端口。
1) 用户通过SMTP协议将自己的邮件推送到服务器上。
2)
服务器根据邮件中的域名进行解析,然后和对方的邮件服务器建立连接,并发送邮件,发送的协议依然遵从SMTP
3)
对方用户上线的时候,自动从自己的邮局服务器中PULL拉取新收到的邮件。这里是遵循的POP3协议,POP3是专门用来下载的协议。
解构通信实体
- UA(用户代理):端用户的邮件程序,提供用户和邮件服务器之间的接口
- MTA(消息转发代理):负责发送/接收电子邮件,并向邮件发件人报告有关邮件传输的状态信息
- Mailbox:用于存储邮件
- 协议:
- 发送协议:SMTP
- 接受协议:POP3/IMAP
- 发送协议:SMTP
解构通信动作
- 组成:创建消息和回复的过程
- 传输:指将消息从发送者传送到接收者
- 回复:指的是将消息处理的情况告知消息发起者的过程。
- 展示:展示消息
- 处置:指的是消息在接收者读取之后发生的情况
Email地址
地址格式:user@dns-address
该Email地址全球唯一,因为:
- dns-address全球唯一
- dns-address中的用户在dns-address中唯一
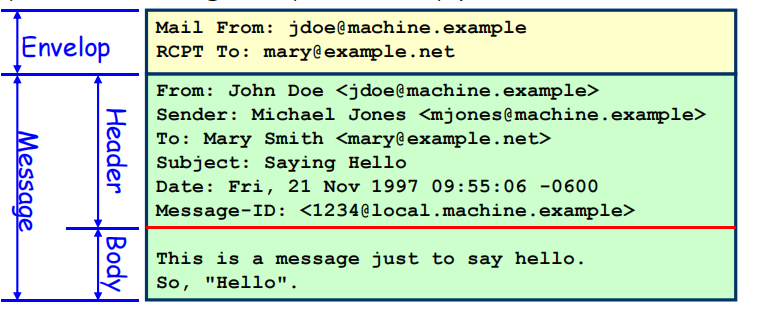
信息传输格式:
- Envelop:包含传输所需的所有信息
- Message
- Header:包含收发双方信息,时间戳,标题等额外信息
- Header和Body之间需要有一行空行
- Body:正文部分
MIME拓展
拓展原因:最开始只能传输ASCII码,后续的EMAIL传输必须兼容中文,日文,音频视频等二进制文件以及WORD等应用程序文件。MIME拓展非常的“聪明“,它在不修改现有EMAIL格式的情况下,成功实现了以上功能。
大概的工作过程:
1)
UA对非ASCII内容启动MIME编码器,将内容转换成一长串由7位标准ASCII字符组成的文本
2) 然后,UA将这段ASCII文本作为邮件正文,并通过SMTP协议发送出去。
3)
中间的邮件服务器(SMTP服务器)收到的是一封看起来完全正常的、只包含ASCII字符的邮件。
4)
接收方的UA检查邮件头,发现了MIME相关的字段(如Content-Type: image/jpeg)。它立刻明白邮件正文并非普通文本,而是一个经过编码的JPEG图片。
5)
UA自动启动MIME解码器,将那段长长的7位ASCII字符串解码,还原成原始的图片二进制数据(非ASCII码)。
Mail的传输
SMTP协议
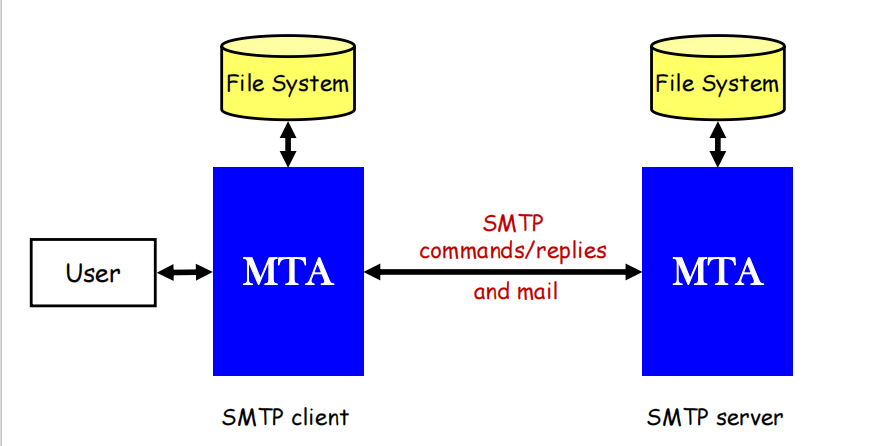
如图所示,SMTP是一个简单的,仅支持ASCII传输的协议。采用TCP协议通信。
两个Mail Transfer Agent之间通过SMTP协议进行通信
POP协议
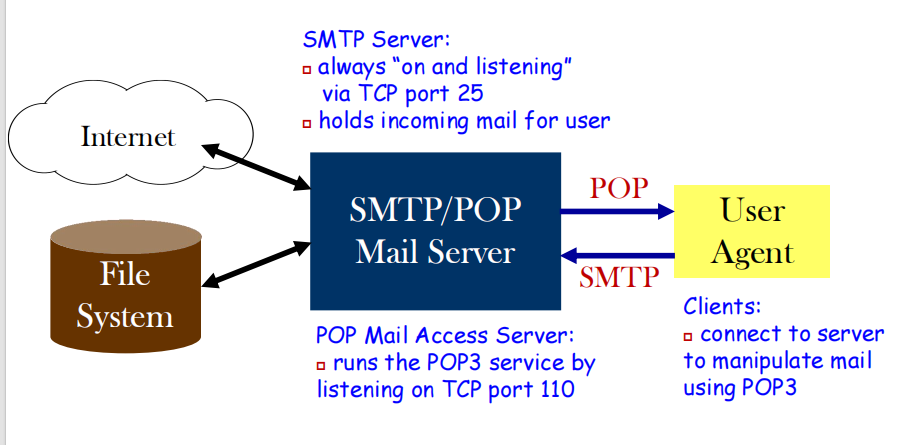
如图所示,POP协议用于将邮件发送到客户端。
由于请求下载的服务肯定和传输的服务不一样,因此需要重新定义一个协议来专门用于下载收到的mail。监听110端口,提供下载服务。
IMAP协议
目的:为了解决POP协议的不同步问题。POP协议在下载之后,服务端就会把这个文件删除掉,但是对于多端用户,他们希望能够同步收件,因此采用IMAP协议来解决这个问题。
WWW(万维网)
核心:一个分布式超媒体系统,信息储存在Web服务器上,通过超链接这些分散的信息连接成一个巨大的“网”。
主要技术:
- 客户端/服务器模式
- URL:统一资源定位符,每一个资源都有一个唯一的全球通用的地址
-
HTML:超文本标记语言,一种标记语言,通过各类标签定义网页的结构和内容
-
HTTP:超文本传输协议,当你在浏览器地址栏输入一个URL并回车时,浏览器就会按照HTTP协议的格式,生成一个“请求(Request)”消息发送给服务器。服务器收到后,也按照HTTP协议的格式,将网页的HTML内容打包成一个“响应(Response)”消息发回给浏览器。
- Search
engine:搜索引擎,万维网的地图。能够爬取海量网页,支持关键词索引到大量的信息
客户端:浏览器
两大职责:
- 获取信息,从服务器获取需要的信息
- 显示信息,拿到需要的信息之后,按照HTML的规则渲染为可以看懂的界面
流程如下:
- 确定URL:
浏览器首先明确目标,确认需要访问的完整地址就是
http://www.abc.com/example.html。
- 询问DNS:
浏览器知道计算机网络不认识域名(www.abc.com),只认识IP地址。于是它会去问DNS服务器:“www.abc.com的IP地址是多少?”
(这是我们之前讨论过的DNS解析过程)。
- 建立TCP连接:
DNS返回了IP地址后,浏览器会与该IP地址对应的服务器尝试建立一条稳定可靠的通信线路,这就是TCP连接。这就像打电话前先要拨号,等对方接通。
- 发送HTTP请求:
连接建立后,浏览器会通过这条线路,用HTTP协议的格式发送一个请求报文,内容大致是:“你好,我想要你服务器上的
/example.html 这个文件。”
- 获取嵌入内容: 浏览器收到服务器发回的
example.html
文件后,会快速阅读其中的HTML代码。当它发现代码里还引用了其他资源(比如图片<img>、样式表CSS等),它会为每一个资源重复第4步,再次发送HTTP请求去获取它们。
- 显示页面:
当所有需要的组件(HTML文本、所有图片等)都下载完毕后,浏览器会将它们“组装”起来,最终在你屏幕上渲染出完整的网页。
- 释放TCP连接:
任务完成后,浏览器会断开与服务器的TCP连接,以释放网络资源。
服务端:Web服务器
两大职责:
- 储存Web文档,存放文件信息
- 响应浏览器的请求,回应被请求的信息
流程如下:
- 接受TCP连接:
Web服务器24小时不间断地在监听指定的端口(HTTP通常是80端口)。当你的浏览器请求建立连接时,它会立刻接受连接,表示“电话已接通,可以开始通话”。
- 获取页面路径:
服务器通过TCP连接收到了你的浏览器发来的HTTP请求。它会解析这个请求,并从中得知你想要的是
/example.html 这个文件。
- 获取文件:
服务器根据这个路径,在自己的硬盘(disk)上找到 example.html
这个文件。
- 发送文件内容:
服务器将该文件的内容读取出来,打包成一个HTTP响应报文,通过已经建立好的TCP连接发回给你的浏览器。
- 释放TCP连接:
发送完毕后,服务器也同样会关闭TCP连接。然后它会继续回到监听状态,等待下一个客户端的请求。
Web 文件
静态Web页面
- 核心思想:
“所见即所得”。网页文件在被用户请求之前就已经被创建好了,并原封不动地存储在服务器的硬盘上。
- 内容: 内容是固定不变的
(unchanging)。无论谁在什么时间访问,看到的都是完全相同的内容。
- 技术:
直接用HTML语言编写,文件后缀通常是
.html或.htm。
动态Web页面
- 核心思想:
网页内容是在用户请求之时,由服务器动态生成的。服务器上存储的不是一个静态的HTML文件,而是一个程序。
- 内容: 内容是可变的 (Can
change)。可以根据访问时间、访问者身份、用户输入等条件,生成完全不同的页面。
- 技术: 在服务器端 (server side)
运行的程序或脚本,如 PHP, ASP, JSP, Python, Node.js
等。这些程序的后缀通常是
.php,.asp等。
活跃Web页面
- 核心思想:
页面的变化发生在文档被加载到浏览器之后,由运行在浏览器中的程序驱动。
- 内容:
可以在不刷新页面的情况下,响应用户的操作(如点击、拖拽)并改变页面显示。
- 技术: 在客户端 (client side) 运行的程序。过去可能是Java Applet,但现在几乎完全是指JavaScript。
HTTP协议
特点
- 遵循客户端/服务器架构
- 同步请求/应答
- 健忘性:服务器不会记录任何关于之前请求的信息。
工作流程
- 分析URL:
浏览器从用户点击的链接中解析出协议、域名和路径。
- DNS解析:
浏览器向DNS服务器查询域名对应的IP地址。
- 建立TCP连接:
浏览器与获取到的IP地址建立TCP连接。
- 发送HTTP请求:
浏览器通过TCP连接,发送一个HTTP请求报文。
- 服务器响应:
服务器处理请求,并将请求的页面(如HTML文件)作为HTTP响应报文发回。
- 释放TCP连接: 通信完成,连接断开。
- 浏览器显示: 浏览器解析收到的HTML文件,并将其渲染成用户看到的网页。
HTTP1.1:性能提升
为了解决HTTP1.0中的停止等待问题,HTTP1.1做了如下提升
- 持久连接,不每次传输完页面就停止连接
- 流水线
- 增强的缓存选项
- 支持压缩
1.Persistent connections (持久连接)
- 定义: Use the same TCP connection(s) for
transfer of multiple files
(使用同一个TCP连接来传输多个文件)。
- 工作方式:
浏览器在第一次与服务器建立TCP连接后,不再立即关闭它,而是保持这条连接“存活”(Keep-Alive)。后续请求其他文件(如图片、脚本)时,会直接复用这条已经建立好的连接。
- 好处:
Reduces packet traffic significantly(显著减少了数据包流量)。它几乎完全消除了为每个文件重复建立和关闭连接所带来的巨大开销,极大地降低了延迟。
- 类比: 就像你打电话给披萨店。HTTP/1.0是“打一次电话点一个披萨,挂断;再打一次电话点一份鸡翅,挂断”。而HTTP/1.1的持久连接是“打一次电话,把披萨、鸡翅、可乐全部点完,然后再挂断”。
2. Pipelining (流水线)
- 定义:
Multiple HTTP requests can be written out to a socket together without waiting for the corresponding responses(可以将多个HTTP请求一次性写入套接字,而无需等待相应的响应)。
- 工作方式:
这个技术构建在持久连接之上。在一条持久连接中,浏览器可以像“连珠炮”一样,把对图片1、图片2、图片3的请求一次性全部发送给服务器,然后等待服务器按顺序依次返回响应。
- 好处: Pack several HTTP requests into one
TCP/IP packet
(将多个HTTP请求打包进一个TCP/IP包)。它消除了单个请求之间的等待时间。在HTTP/1.0中,必须等上一个请求的响应回来后,才能发送下一个请求。而流水线技术则让请求可以“批量”发送,大大减少了网络往返的次数。
- 类比: 还是点餐的例子。持久连接是“打一个电话点完所有菜”。流水线技术则更进一步,是你对服务员说:“我要一个披萨、一份鸡翅、一杯可乐”,一口气把所有需求都告诉他,然后等着他按顺序把东西一样一样给你端上来。
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

