


Motivation
对于正常的一个训练流程,为了让大模型更好的适配下游任务,我们需要进行二次训练。二次训练的过程中,我们需要对每一层的参数矩阵进行求导,然后进行梯度下降反向传播的方法,来更新其权重,本质是极大似然估计。但是,鉴于现在的预训练模型越来越大,动辄百亿乃至千亿的参数,让个人用户以及小公司直接对大模型进行二次训练时不现实的。其算力成本过大。因此,就有了LoRA这样的微调技术的出现
Procedure
我们知道,正常的二次训练的更新的流程为:
那么,二次训练的难点就在于,这个
有的兄弟,有的。我们先设
我们可以这样考虑。对于初始模型的权重
LoRA的中心思想就出现了:参数化
但是,好奇的同学就会说了,那你这个参数化的
诶~这里就是LoRA的第二个trick了,我们知道,微调数据集的数据量往往远小于预训练的数据集,因此,其实它对于
但是要注意,虽然形式上映射回了高维空间,但是其信息量和在低维空间是一致的,因此,这样的训练确实减少了参数,但是并不能等价于直接训练的效果。它也确实丢失了一部分信息~
下面上图:
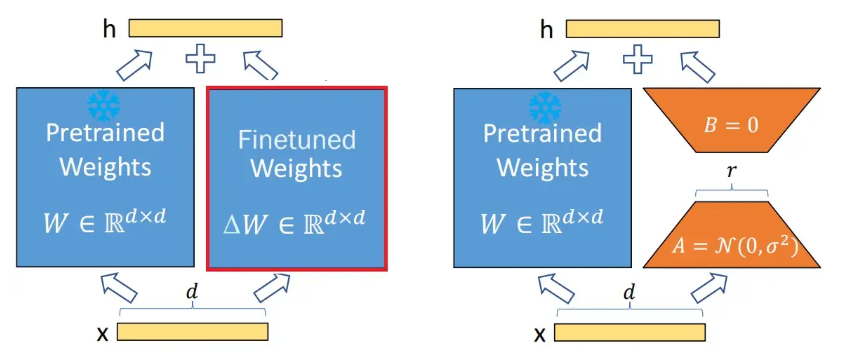
左边是直接二次训练的图,右侧是LoRA的图。
(这里还有一个小小的trick,为了使训练的初始状态和原模型一样,我们要让
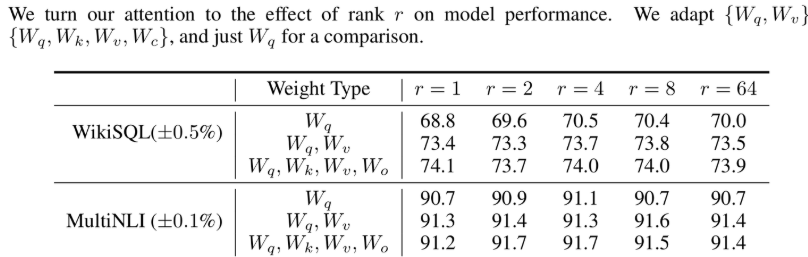
关于超参数r的选取
我们知道了,LoRA的本质,就是把增量矩阵参数化,然后映射到低维空间进行学习。那么,映射到的空间维数越低,丢失的信息就越多,同样训练起来的算力需求也就越低。映射到的空间维数越高,获取的信息就越多,当然同样也更容易过拟合(r不是越高越好),因此,需要平衡r的选择。这里论文作者给出了他的实验结果
如果您喜欢我的文章,可以考虑打赏以支持我继续创作.

